






Leadership GPU Server, Built for Trailblazers in HPC & AI
Note: IBM announced has announced the withdrawal and end of sale of AC922. Please Contact Microway for guidance on alternate solutions.
Power Systems AC922 is a leadership HPC & AI server with 2 POWER9 with Enhanced NVLink CPUs and 4-6 NVIDIA Tesla V100 GPUs in 2U. These same servers are deployed at the leadership CORAL Supercomputers at Oak Ridge National Lab (ORNL) and Lawrence Livermore National Lab (LLNL).
Power Systems AC922 delivers 3 groundbreaking advancements every HPC & AI leader needs:
-
Coherence: for World’s Simplest GPU Programming
-
Nearly 5X the CPU:GPU Bandwidth; nearly 10X the Data Throughput
-
POWER9 with NVLink CPU
Features
Coherence: for World’s Simplest GPU Programming

Finally, the CPU and GPU speak the same language. The first and only shared (coherent) memory space between CPU and NVIDIA® Tesla® GPU is here. Eliminate hundreds to thousands of lines of specialized programming and data transfers: only with POWER9 and Tesla V100 on Power Systems AC922.
Nearly 5X the CPU:GPU Bandwidth; nearly 10X the Data Throughput

AC922 is the only platform with Enhanced NVLink from CPU:GPU, offering up to 150GB/sec of bi-directional bandwidth for data-intensive workloads. That’s almost 5X the CPU:GPU bandwidth of PCI-E. Each GPU is serviced with 300GB/sec of NVLink bandwidth, nearly 10X the Data Throughput of PCI-E x16 3.0 platforms.
POWER9 with NVLink CPU
The POWER9 platform features up to 24 cores, 3 high bandwidth interfaces to accelerators (PCI-E Gen4, OpenCAPI, Enhanced NVLink), overwhelming memory bandwidth, and high socket throughput.
- Two, four, or six NVIDIA Tesla V100 GPUs with NVLink GPUs (6 GPU configuration only with water cooling)
- NVLink connectivity from CPU:GPU and GPU:GPU for data-intensive and multi-GPU applications
- Up to 48 IBM POWER processor cores (each supporting 4 threads)
- Up to 2TB system memory with memory bandwidth of up to 340GB/sec
- Support for high-speed InfiniBand fabrics and ethernet connectivity
- NVIDIA CUDA Toolkit installed and configured – ready to run GPU jobs!
Specifications
- (2) IBM POWER9 with Enhanced NVLink CPUs
(with 24, 22, 18, or 10 core configurations) - Up to 2TB of high-performance DDR4 ECC/Registered Memory (16 slots)
- Up to (2) Hot-Swap 2.5” 6Gbps drives
- Six SXM2 slots for NVIDIA Tesla V100 GPUs,
each with Six Next-Generation NVIDIA NVLink™ “Bricks” (300GB/s bidirectional BW) - One shared PCI-Express 4.0 x16 low-profile slot for EDR/HDR InfiniBand (includes muliti-socket host-direct)
- Removable Storage: one front and one rear USB 3.0 port
- Options for Gigabit Ethernet, 10G or 100G ethernet
- IPMI 2.0 with Dedicated LAN Support
- Dual, Redundant 2000W Power Supplies
or Optional NVMe SSD or Burst Buffer
Accessories/Options
- ConnectX-6 200Gb HDR or ConnectX-5 100Gb EDR InfiniBand
- High-speed NVMe flash storage and optional Burst Buffer
- PGI Accelerator Compilers (with OpenACC support) for OpenPOWER
- IBM XL compilers and tools
Support
Supported for Life
Our technicians and sales staff consistently ensure that your entire experience with Microway is handled promptly, creatively, and professionally.
Telephone support is available for the lifetime of your server(s) by Microway’s experienced technicians. After the initial warranty period, hardware warranties are offered on an annual basis. Out-of-warranty repairs are available on a time & materials basis.
Price
System Price: $55000 to $75000
Each Microway system is customized to your requirements. Final pricing depends upon configuration and any applicable educational or government discounts.
Call a Microway Sales Engineer for Assistance : 508.746.7341 or
Click Here to Request More Information.
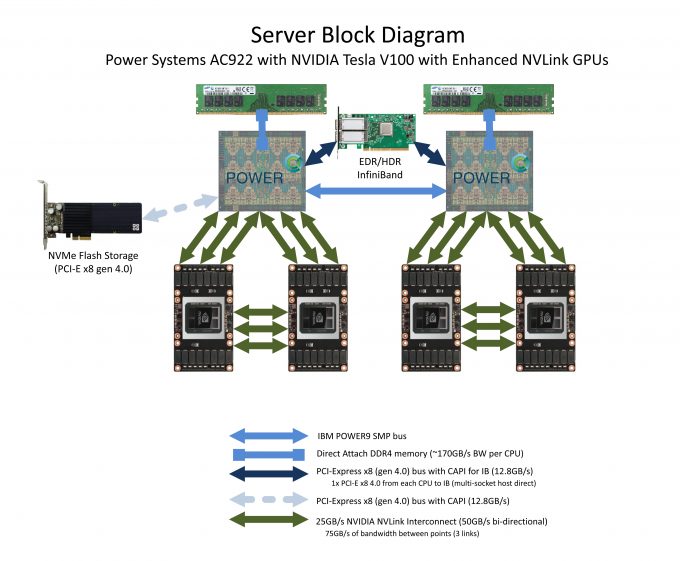
Block diagram of Power Systems AC922 with Tesla V100 with NVLink GPUs







