The next generation NVIDIA Volta architecture is here. With it comes the new Tesla V100 “Volta” GPU, the most advanced datacenter GPU ever built.
Volta is NVIDIA’s 2nd GPU architecture in ~12 months, and it builds upon the massive advancements of the Pascal architecture. Whether your workload is in HPC, AI, or even remote visualization & graphics acceleration, Tesla V100 has something for you.

Two Flavors, one giant leap: Tesla V100 PCI-E & Tesla V100 with NVLink
For those who love speeds and feeds, here’s a summary of the key enhancements vs Tesla P100 GPUs
| Tesla V100 with NVLink | Tesla V100 PCI-E | Tesla P100 with NVLink | Tesla P100 PCI-E | Ratio Tesla V100:P100 | |
|---|---|---|---|---|---|
| DP TFLOPS | 7.8 TFLOPS | 7.0 TFLOPS | 5.3 TFLOPS | 4.7 TFLOPS | ~1.4-1.5X |
| SP TFLOPS | 15.7 TFLOPS | 14 TFLOPS | 9.3 TFLOPS | 8.74 TFLOPS | ~1.4-1.5X |
| TensorFLOPS | 125 TFLOPS | 112 TFLOPS | 21.2 TFLOPS 1/2 Precision | 18.7 TFLOPS 1/2 Precision | ~6X |
| Interface (bidirec. BW) | 300GB/sec | 32GB/sec | 160GB/sec | 32GB/sec | 1.88X NVLink 9.38X PCI-E |
| Memory Bandwidth | 900GB/sec | 900GB/sec | 720GB/sec | 720GB/sec | 1.25X |
| CUDA Cores (Tensor Cores) | 5120 (640) | 5120 (640) | 3584 | 3584 |
Selecting the right Tesla V100 for you:
With Tesla P100 “Pascal” GPUs, there was a substantial price premium to the NVLink-enabled SXM2.0 form factor GPUs. We’re excited to see things even out for Tesla V100.
However, that doesn’t mean selecting a GPU is as simple as picking one that matches a system design. Here’s some guidance to help you evaluate your options:


Performance Summary
Increases in relative performance are widely workload dependent. But early testing demonstates HPC performance advancing approximately 50%, in just a 12 month period.
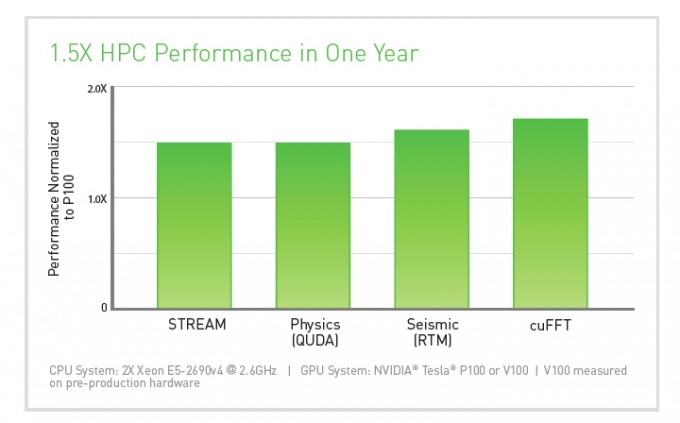
If you haven’t made the jump to Tesla P100 yet, Tesla V100 is an even more compelling proposition.
For Deep Learning, Tesla V100 delivers a massive leap in performance. This extends to training time, and it also brings unique advancements for inference as well.
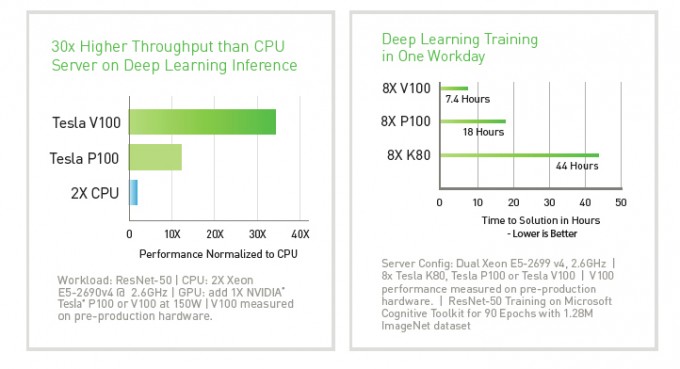
Enhancements for Every Workload
Now that we’ve learned a bit about each GPU, let’s review the breakthrough advancements for Tesla V100.
Next Generation NVIDIA NVLink Technology (NVLink 2.0)
NVLink helps you to transcend the bottlenecks in PCI-Express based systems and dramatically improve the data flow to GPU accelerators.
The total data pipe for each Tesla V100 with NVLink GPUs is now 300GB/sec of bidirectional bandwidth—that’s nearly 10X the data flow of PCI-E x16 3.0 interfaces!
Bandwidth
NVIDIA has enhanced the bandwidth of each individual NVLink brick by 25%: from 40GB/sec (20+20GB/sec in each direction) to 50GB/sec (25+25GB/sec) of bidirectional bandwidth.
This improved signaling helps carry the load of data intensive applications.
Number of Bricks
But enhanced NVLink isn’t just about simple signaling improvements. Point to point NVLink connections are divided into “bricks” or links. Each brick delivers
From 4 bricks to 6
Over and above the signaling improvements, Tesla V100 with NVLink increases the number of NVLink “bricks” that are embedded into each GPU: from 4 bricks to 6.
This 50% increase in brick quantity delivers a large increase in bandwidth for the world’s most data intensive workloads. It also allows for more diverse set of system designs and configurations.
The NVLink Bank Account
NVIDIA NVLink technology continues to be a breakthrough for both HPC and Deep Learning workloads. But as with previous generations of NVLink, there’s a design choice related to a simple question:
Where do you want to spend your NVLink bandwidth?
Think about NVLink bricks as a “spending” or “bank account.” Each NVLink system-design strikes a different balance between where they “spend the funds.” You may wish to:
- Spend links on GPU:GPU communication
- Focus on increasing the number of GPUs
- Broaden CPU:GPU bandwidth to overcome the PCI-E bottleneck
- Create a balanced system, or prioritize design choices solely for a single workload
There are good reasons for each, or combinations, of these choices. DGX-1V, NumberSmasher 1U GPU Server with NVLink, and future IBM Power Systems products all set different priorities.
We’ll dive more deeply into these choices in a future post.
Net-net: the NVLink bandwidth increases from 160GB/sec to 300GB/sec (bidirectional), and a number of new, diverse HPC and AI hardware designs are now possible.
Programming Improvements
Tesla V100 and CUDA 9 bring a host of improvements for GPU programmers. These include:
- Cooperative Groups
- A new L1 cache + shared memory, that simplifies programming
- A new SIMT model, that relieves the need to program to fit 32 thread warps
We won’t explore these in detail in this post, but we encourage you to read the following resources for more:
What does Tesla V100 mean for me?
Tesla V100 GPUs mean a massive change for many workloads. But each workload will see different impacts. Here’s a short summary of what we see:
- An increase in performance on HPC applications (on paper FLOPS increase of 50%, diverse real-world impacts)
- A massive leap for Deep Learning Training
- 1 GPU, many Deep Learning workloads
- New system designs, better tuned to your applications
- Radical new, and radically simpler, programming paradigms (coherence)
