This article provides in-depth discussion and analysis of the 14nm Xeon E5-2600v4 series processors (formerly codenamed “Broadwell-EP”). “Broadwell” processors replace the previous 22nm “Haswell” microarchitecture and are available for sale as of March 31, 2016. For an introduction, read our blog post Intel Xeon E5-2600 v4 “Broadwell” Processor ReviewNote: these have since been superceded by the Intel Xeon Processor Scalable Family CPUs.
Important changes available in E5-2600v4 “Broadwell-EP” include:
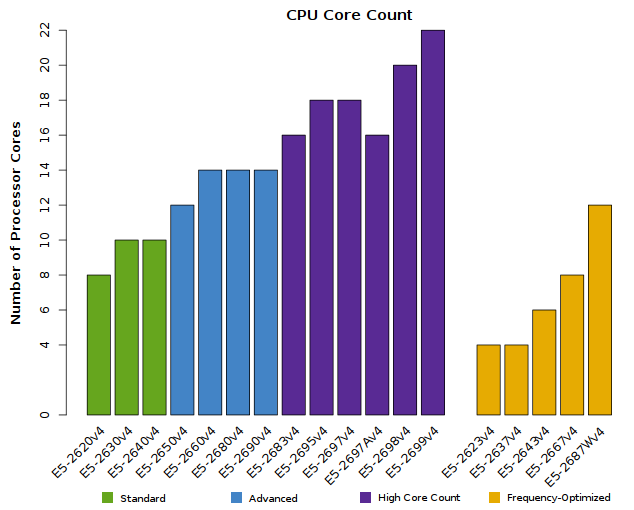
- Up to 22 processor cores per socket (with options for 4-, 6-, 8-, 10-, 12-, 14-, 16-, 18-, and 20-cores)
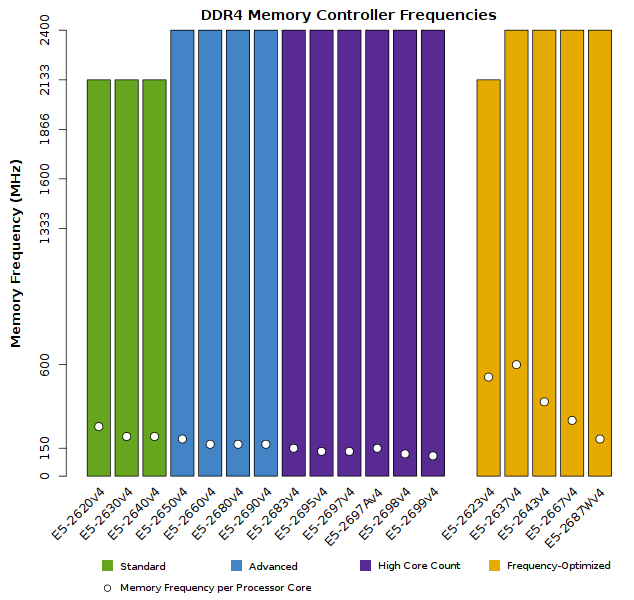
- Support for DDR4 memory speeds up to 2400MHz
- Floating Point Instruction performance improvements:
- Faster floating point multiplier completes operations in 3 cycles (down from 5 cycles)
- 1024 Radix divider for reduced latency
- Split Scalar divides for increased parallelism/bandwidth
- Faster vector Gather
- As introduced with Haswell, Broadwell continues to support AVX2 and FMA3 instructions for significant speedups of floating-point multiplication and addition operations
- Extract more parallelism in scheduling micro-operations:
- Reduced instruction latencies on ADC, CMOV and PCLMULQDQ
- Larger out-of-order scheduler, with 64 entries (up from 60 entries)
- Improved address prediction for branches and returns, with an expanded 10-way Branch Prediction Unit Target Array (up from 8-way)
- Improved performance on large data sets:
- Larger L2 Translation Lookaside Buffer (TLB), with 1.5k entries (up from 1K entries)
- A new L2 TLB for 1GB pages (with 16 entries)
- Addition of a second TLB page miss handler for parallel page walks
With a product this complex, it’s very difficult to cover every aspect of the design. Here, we concentrate primarily on the performance of the processors for HPC applications.
Exceptional Computational Performance
The Xeon E5-2600v4 processors provide the highest performance available to date in a socketed CPU. Many of the higher-end models provide well over 500 GFLOPS (more than half a TFLOPS). Much of this performance is made possible through the use of AVX2 with FMA3 instructions. The plot below compares the peak performance of these CPUs with and without FMA instructions:
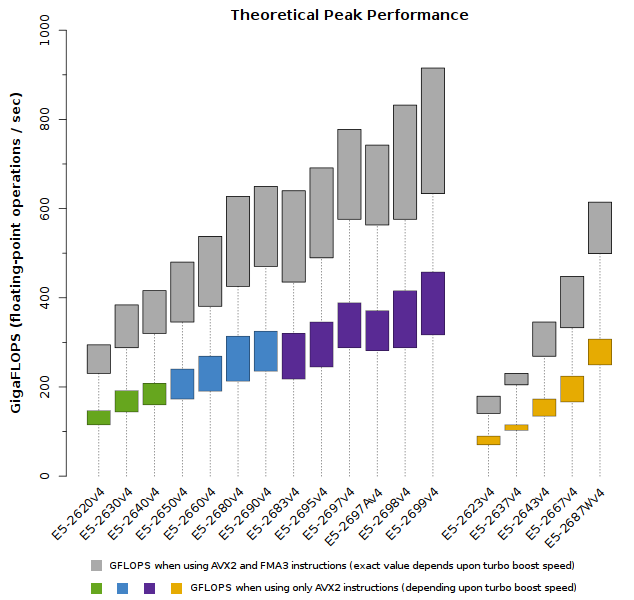
The colored bars indicate performance using only AVX instructions; the grey bars indicate theoretical peak performance when using AVX with FMA. Note that only a small set of codes will be capable of issuing almost exclusively FMA instructions (e.g., LINPACK). Most applications will issue a variety of instructions, which will result in lower than peak FLOPS. Expect the achieved performance for well-parallelized & optimized applications to fall between the grey and colored bars.
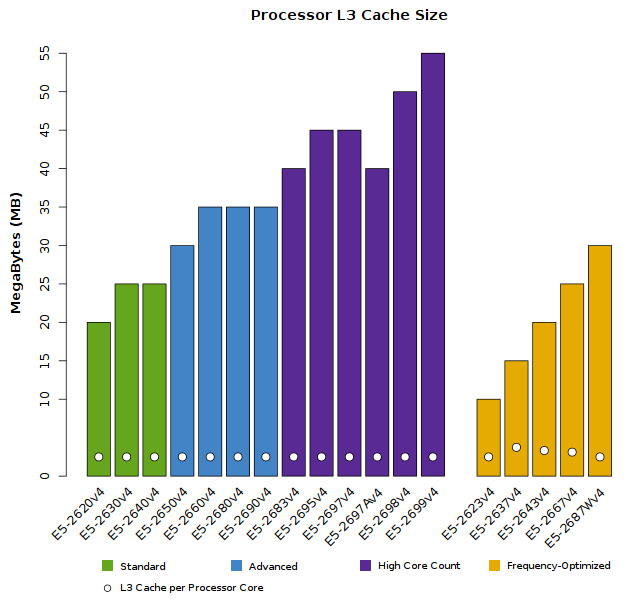
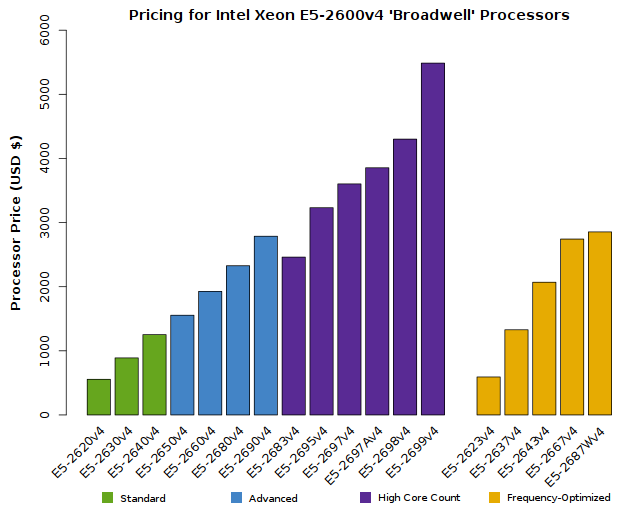
Intel Xeon E5-2600v4 Series Specifications
The tabs below compare the features and specifications of the new model line. Intel has divided the CPUs into several groups:
- Standard: cost-effective CPUs with moderate performance
- Advanced: CPUs offering the highest performance for most applications
- High Core Count: ideal for highly multi-threaded applications; CPUs providing the highest number of processor cores (sometimes sacrificing clock frequency in favor of core count)
- Frequency Optimized: ideal for non-parallel/single-threaded applications; CPUs with the highest clock speeds (sacrificing number of cores in order to provide the highest frequencies)
Although these processors introduce significant performance increases, technical readers will see that many of the changes are incremental: increased core counts, improved DDR memory speed, etc. However, processor clock speeds/frequencies have not seen significant improvements.
In fact, in some cases the CPU frequency has been lowered from the previous models. Processor frequency and Turbo Boost behavior have changed fairly significantly in the last two CPU releases (“Haswell” and “Broadwell”). Those metrics are discussed in further detail in the next section.
Clock Speeds & Turbo Boost in Xeon E5-2600v4 series “Broadwell” processors
With each new processor line, Intel introduces new architecture optimizations. The design of the “Broadwell” architecture acknowledges that highly-parallel/vectorized applications place the highest load on the processor cores (requiring more power and thus generating more heat). While a CPU core is executing intensive vector tasks (AVX instructions), the clock speed may be reduced to keep the processor within its power limits (TDP).
In effect, this may result in the processor running at a lower frequency than the “base” clock speed advertised for each model. For that reason, each “Broadwell” processor is assigned two “base” frequencies:
- AVX mode: due to the higher power requirements of AVX instructions, clock speeds may be somewhat lower while executing AVX instructions *
- Non-AVX mode: while not executing AVX instructions, the processor will operate at what would traditionally be considered the “stock” frequency
* a CPU core will return to Non-AVX mode 1 millisecond after AVX instructions complete
It is worth noting that these modes are isolated to each core. Within a given CPU, some cores may be operating in AVX mode while others are operating in Non-AVX mode. In the previous generation, AVX instructions running on a single core would cause all cores to run in AVX mode.
AVX and Non-AVX Turbo Boost
Just as in previous architectures, “Broadwell” CPUs include the Turbo Boost feature which allows each processor core to operate well above the “base” clock speed during most operations. The precise clock speed increase depends upon the number & intensity of tasks running on each CPU. However, Turbo Boost speed increases also depend upon the types of instructions (AVX vs. Non-AVX).
The two plots below show that processor clock speeds can be categorized as:
- All cores on the CPU actively running Non-AVX instructions
- All cores on the CPU actively running AVX instructions
- A single active core running Non-AVX instructions (all other cores on the CPU must be idle)
- A single active core running AVX instructions (all other cores on the CPU must be idle)
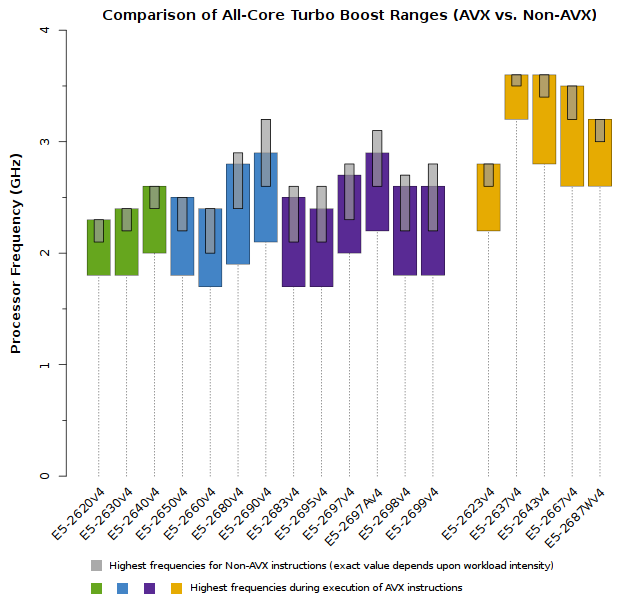
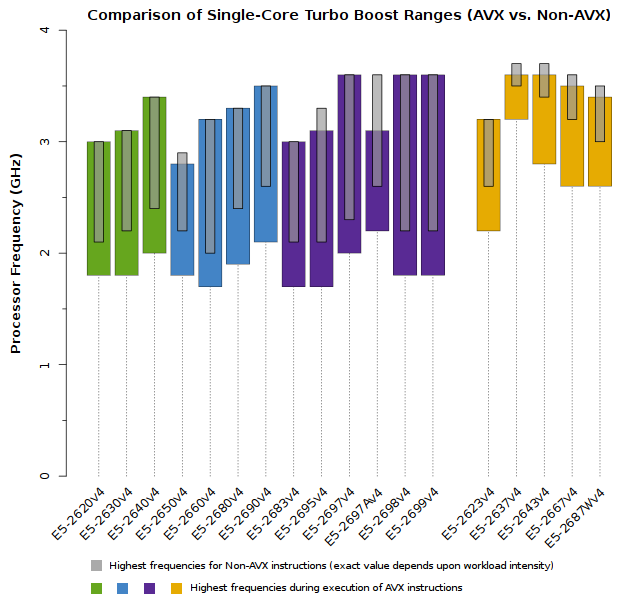
Note that despite the clear rules stated above, each value is still a range of clock speeds. Because workloads are so diverse, Intel is unable to guarantee one specific clock speed for AVX or Non-AVX instructions. Users are guaranteed that cores will run within a specific range, but each application will have to be benchmarked to determine which frequencies a CPU will operate at.
When examining the differences between AVX and Non-AVX instructions, notice that Non-AVX instructions typically result in no more than a 100MHz to 200MHz increase in the highest clock speed. However, AVX instructions may cause clock speeds to drop by 300MHz to 400MHz if they are particularly intensive.
Recall that AVX2 introduces support for both integer and floating-point instructions, which means any compute-intensive application will be using such instructions (if it has been properly designed and compiled). HPC users should expect their processors to be running in AVX mode most of the time.
Top Clock Speeds for Specific Core Counts
When workloads leave some CPU cores idle, the Xeon E5-2600v4 processors are able to use that headroom to increase the clock speed of the cores which are performing work. Just as with other Turbo Boost scenarios, the precise speed increase will depend upon the CPU model. It will also depend upon how many CPU cores are active.
We advise users to consider how many CPU cores their application is able to saturate. The tabs below detail the peak Turbo Boost frequencies for each CPU model, sorted by the number of active cores:
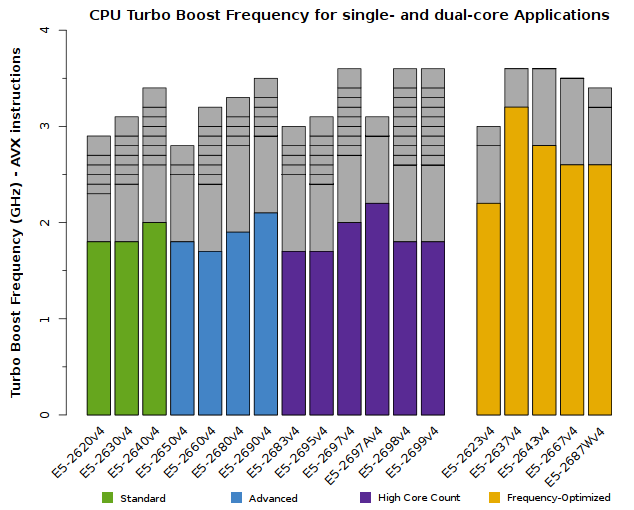
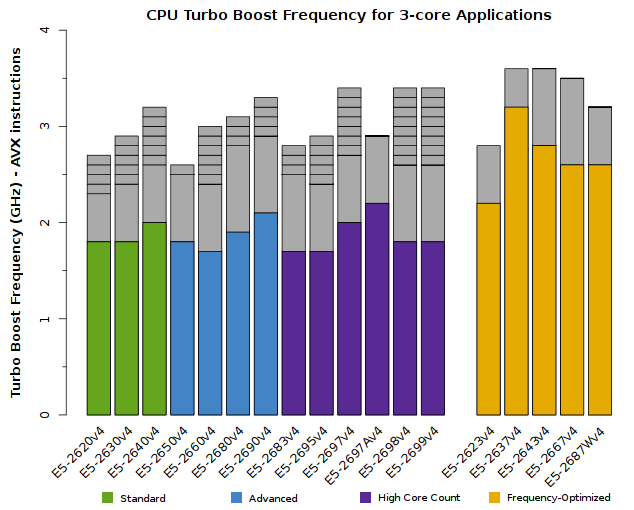
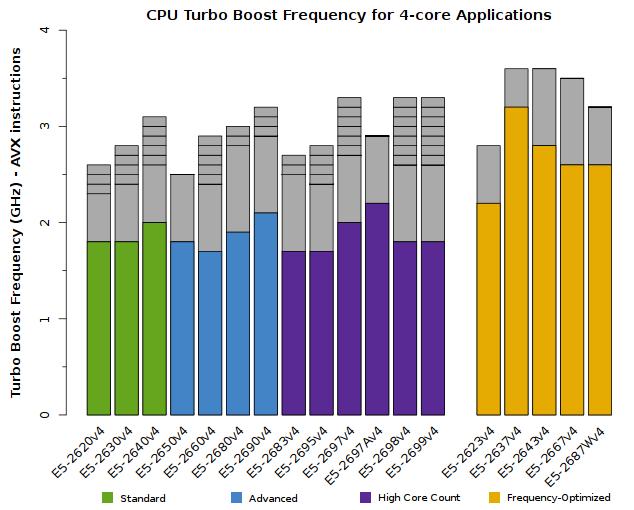
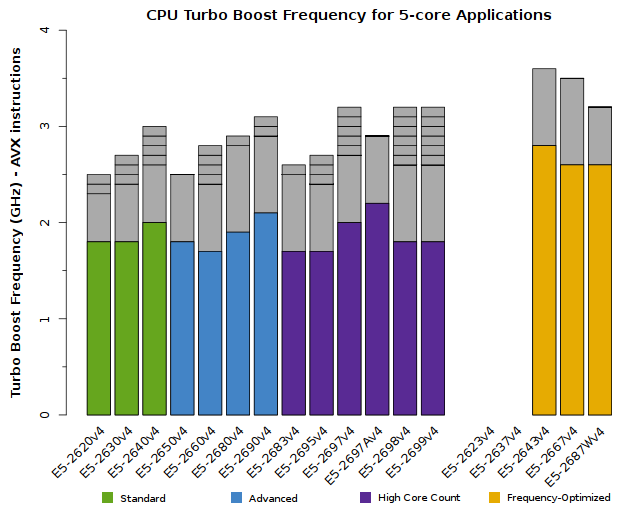
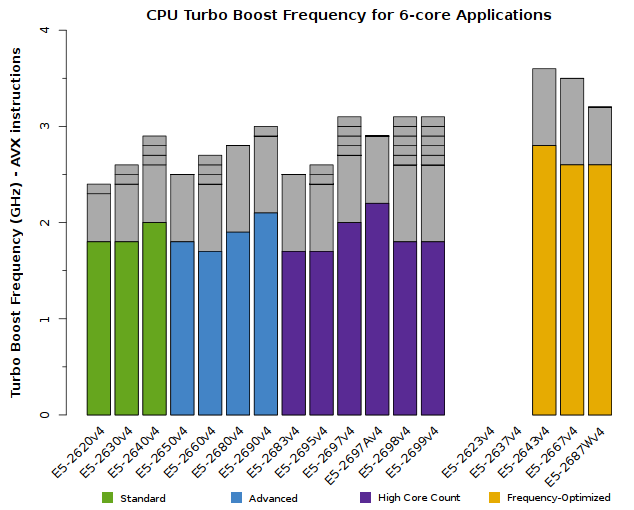
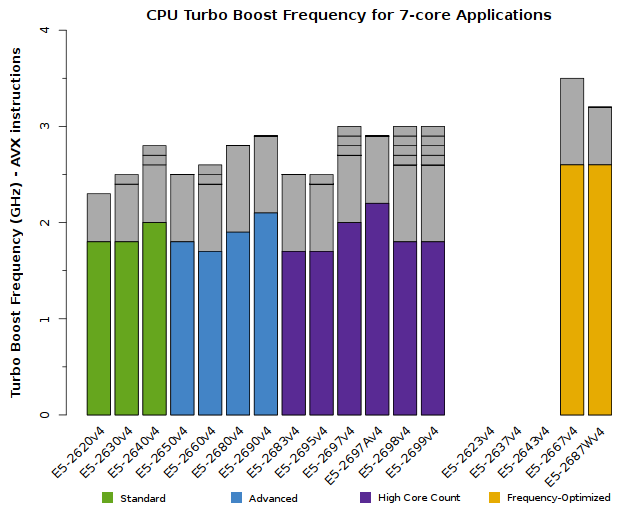
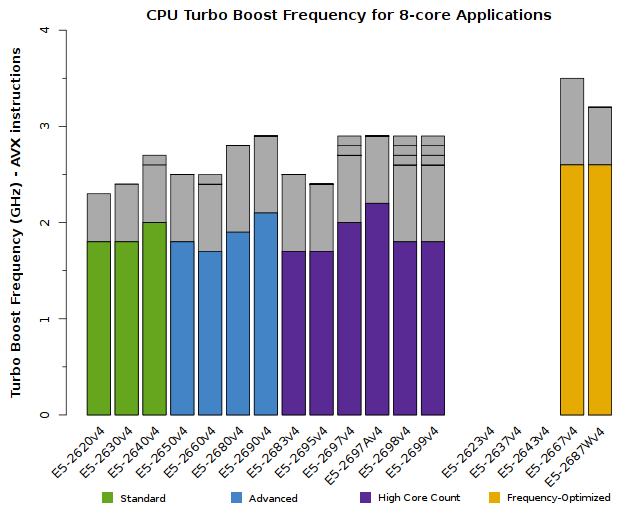
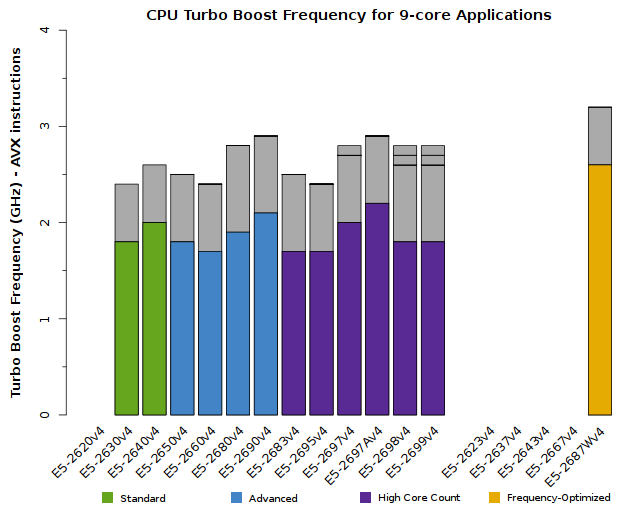
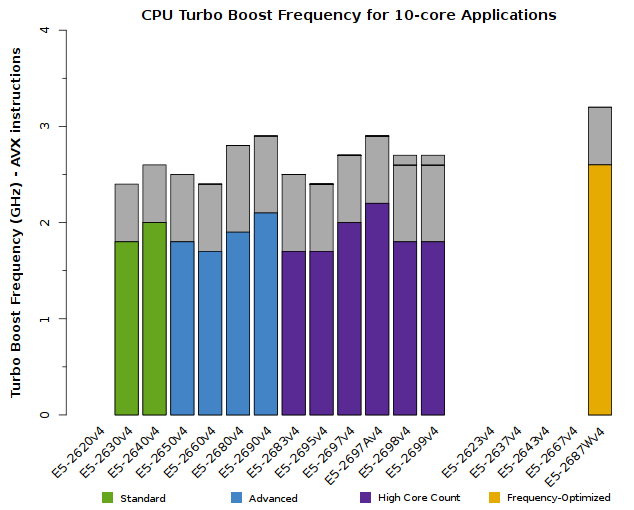
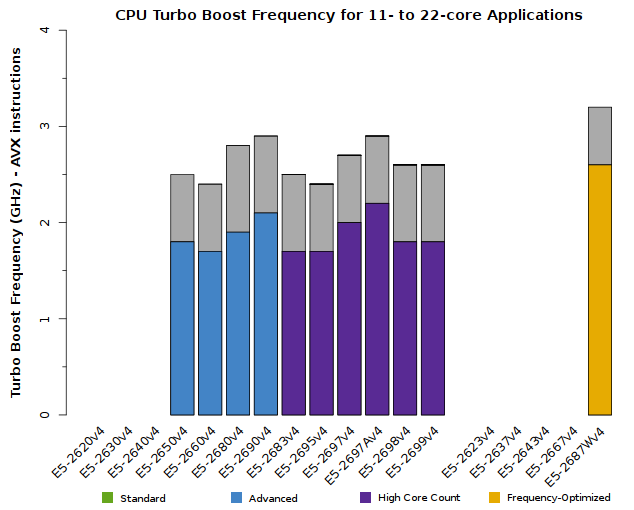
All of the above plots show CPU frequencies for applications utilizing AVX instructions. The colored bars indicate the worst-case scenario – CPUs will run at least this fast. The grey bars indicate the expected clock speeds for most workloads.
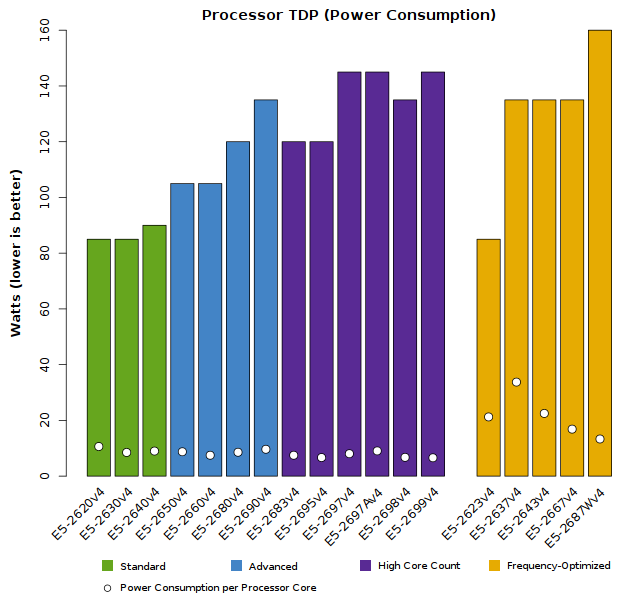
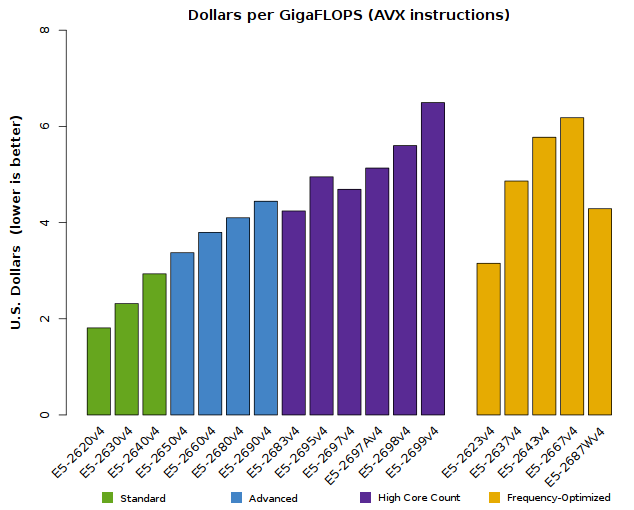
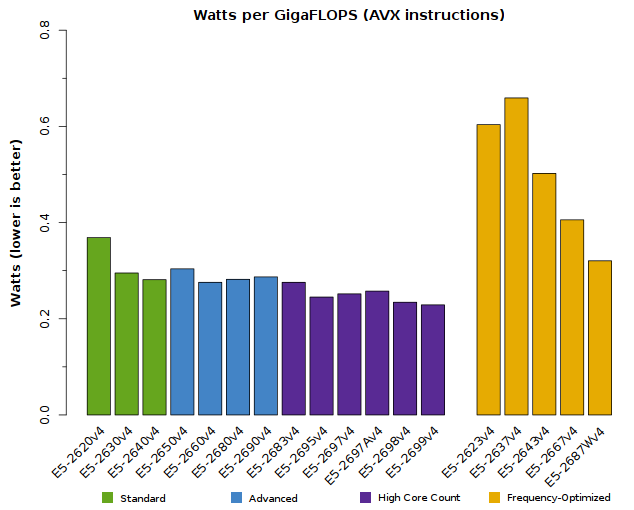
Cost-Effectiveness and Power Efficiency of Xeon E5-2600v4 CPUs
The “Broadwell-EP” processors have nearly the same price structure and power requirements as earlier Xeon E5-2600 products, so their cost-effectiveness and power-efficiency should be quite attractive to HPC users. Savvy readers may find the following facts useful:
- HPC applications run best on the Advanced CPU models; they typically do not scale well on the High-Core-Count models.
- The High-Core-Count models are more common in Enterprise and Finance – these carry higher prices than other E5-2600 models.
- The following graphs depict the cost-effectiveness and power-efficiency of only the CPU itself. In many cases, HPC users will find that once they’ve taken the full platform and cluster design into account, the cost-effectiveness of an Advanced CPU may be higher than these plots demonstrate.
Summary of features in Xeon E5-2600v4 “Broadwell-EP” processors
In addition to the capabilities mentioned at the top of this article, these processors include many of the successful features from earlier Xeon designs. The list below provides a summary of relevant technology features:
- Up to 22 processor cores per socket (with options for 4-, 6-, 8-, 10-, 12-, 14-, 16-, 18-, and 20-cores)
- Support for Quad-channel ECC DDR4 memory speeds up to 2400MHz
- Direct PCI-Express (generation 3.0) connections between each CPU and peripheral devices such as network adapters, GPUs and coprocessors (40 PCI-E lanes per socket)
- Floating Point Instruction performance improvements:
- Faster floating point multiplier completes operations in 3 cycles (down from 5 cycles)
- 1024 Radix divider for reduced latency
- Split Scalar divides for increased parallelism/bandwidth
- Faster vector Gather
- As introduced with “Haswell”, “Broadwell” continues to supportAdvanced Vector Extensions (AVX 2.0):
- effectively double the throughput of integer and floating-point operations with math units expanded from 128-bits to 256-bits
- introduce Fused Multiply Add (FMA3) instructions which allow a multiply and an accumulate instruction to be completed in a single cycle (effectively doubling the FLOPS/clock from 8 to 16 for each core of a CPU)
- add support for additional instructions, including Gather and vector shift
- F16C 16-bit Floating-Point conversion instructions accelerate data conversion between 16-bit and 32-bit floating point formats
- Turbo Boost technology improves performance under peak loads by increasing processor clock speeds. With version 2.0, (introduced in “Sandy Bridge”) clock speeds are boosted more frequently, to higher speeds and for longer periods of time. With “Haswell” and “Broadwell”, top clock speeds depend upon the type of instructions (AVX vs. Non-AVX).
- Extract more parallelism in scheduling micro-operations:
- Reduced instruction latencies on ADC, CMOV and PCLMULQDQ
- Larger out-of-order scheduler, with 64 entries (up from 60 entries)
- Introduction of the ADCX and ADOX instructions to speed up cryptography
- Improved address prediction for branches and returns, with an expanded 10-way Branch Prediction Unit Target Array (up from 8-way)
- Improved performance on large data sets:
- Larger L2 Translation Lookaside Buffer (TLB), with 1.5k entries (up from 1K entries)
- A new L2 TLB for 1GB pages (with 16 entries)
- Addition of a second TLB page miss handler for parallel page walks
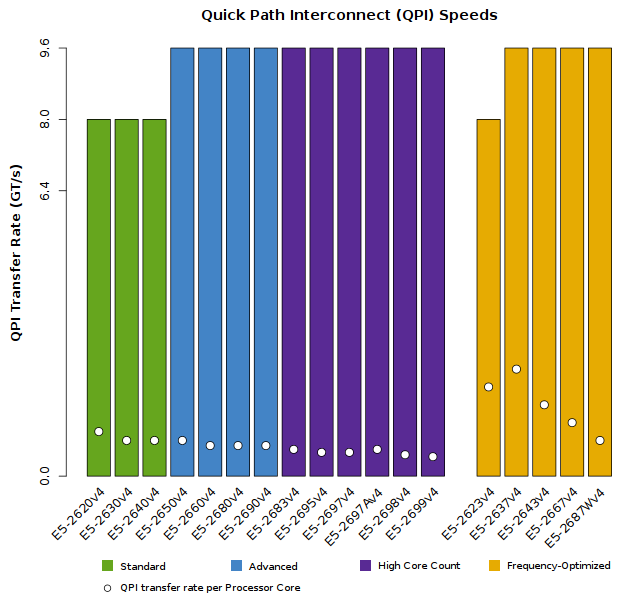
- Dual Quick Path Interconnect (QPI) links between processor sockets improve communication speeds for multi-threaded applications
- Intel Data Direct I/O Technology increases performance and reduces latency by allowing Intel ethernet controllers and adapters to talk directly with the processor cache
- Transactional Synchronization Extensions (TSX) improve the parallelism of multi-threaded applications with synchronization locks
- Introduction of the RDSEED instruction for high-quality, non-deterministic, random seed values
- Advanced Encryption Standard New Instructions (AES-NI) accelerate encryption and decryption for fast, affordable data protection and security
- 32-bit & 64-bit Intel Virtualization Technology (VT/VT-x) forDirected I/O (VT-d) and Connectivity (VT-c) deliver faster performance for core virtualization processes and provide built-in hardware support for I/O virtualization.
- Intel APIC Virtualization (APICv) provides increased virtualization performance
- Hyper-Threading technology allows two threads to “share” a processor core for improved resource usage. Although useful for some workloads, it is not recommended for HPC applications.
- Improved energy efficiency with Per Core P-States and independent uncore frequency control
- Hardware Controlled Power Management for more rapid and efficient decisions on optimal P- and C-State operating point
- DDR4 CRC provides better memory reliability and data integrity by detecting memory bus faults during write
- ECRC for PCI-Express provides optional data integrity protection for systems using PCI-Express switches or bridges