
Now that NVIDIA has launched their new Tesla V100 32GB GPUs, the next questions from many customers are “What is the Tesla V100 Price?” “How does it compare to Tesla P100?” “How about Tesla V100 16GB?” and “Which GPU should I buy?”
Tesla V100 32GB GPUs are shipping in volume, and our full line of Tesla V100 GPU-accelerated systems are ready for the new GPUs. If you’re planning a new project, we’d be happy to help steer you towards the right choices.
Tesla V100 Price
The table below gives a quick breakdown of the Tesla V100 GPU price, performance and cost-effectiveness:
| Tesla GPU model | Price | Double-Precision Performance (FP64) | Dollars per TFLOPS | Deep Learning Performance (TensorFLOPS or 1/2 Precision) | Dollars per DL TFLOPS |
|---|---|---|---|---|---|
| Tesla V100 PCI-E 16GB or 32GB | $10,664* $11,458* for 32GB | 7 TFLOPS | $1,523 $1,637 for 32GB | 112 TFLOPS | $95.21 $102.30 for 32GB |
| Tesla P100 PCI-E 16GB | $7,374* | 4.7 TFLOPS | $1,569 | 18.7 TFLOPS | $394.33 |
| Tesla V100 SXM 16GB or 32GB | $10,664* $11,458* for 32GB | 7.8 TFLOPS | $1,367 $1,469 for 32GB | 125 TFLOPS | $85.31 $91.66 for 32GB |
| Tesla P100 SXM2 16GB | $9,428* | 5.3 TFLOPS | $1,779 | 21.2 TFLOPS | $444.72 |
* single-unit list price before any applicable discounts (ex: EDU, volume)
Key Points
- Tesla V100 delivers a big advance in absolute performance, in just 12 months
- Tesla V100 PCI-E maintains similar price/performance value to Tesla P100 for Double Precision Floating Point, but it has a higher entry price
- Tesla V100 delivers dramatic absolute performance & dramatic price/performance gains for AI
- Tesla P100 remains a reasonable price/performance GPU choice, in select situations
- Tesla P100 will still dramatically outperform a CPU-only configuration
Tesla V100 Double Precision HPC: Pay More for the GPU, Get More Performance
You’ll notice that Tesla V100 delivers an almost 50% increase in double precision performance. This is crucial for many HPC codes. A variety of applications have been shown to mirror this performance boost. In addition, Tesla V100 now offers the option of 2X the memory of Tesla P100 16GB for memory bound workloads.
Tesla V100 can is a compelling choice for HPC workloads: it will almost always deliver the greatest absolute performance. However, in the right situation a Tesla P100 can still deliver reasonable price/performance as well.
Both Tesla P100 and V100 GPUs should be considered for GPU accelerated HPC clusters and servers. A Microway expert can help you evaluate what’s best for your needs and applications and/or provide you remote benchmarking resources.
Tesla V100 for Deep Learning: Enormous Advancement & Value- The New Standard
If your goal is maximum Deep Learning performance, Tesla V100 is an enormous on-paper leap in performance. The dedicated TensorCores have huge performance potential for deep learning applications. NVIDIA has even termed a new “TensorFLOP” to measure this gain. Tesla V100 delivers a 6X on-paper advancement.
If your budget allows you to purchase at least 1 Tesla V100, it’s the right GPU to invest in for deep learning performance. For the first time, the beefy Tesla V100 GPU is compelling for not just AI Training, but AI Inference as well (unlike Tesla P100).
Moreover, only a selection of Deep Learning frameworks are fully taking advantage of the TensorCore today. As more and more DL Frameworks are optimized to use these new TensorCores and their instructions, the gains will grow. Even before many major optimizations, many workloads have advanced 3X-4X.
Finally, there is no more SXM cost premium for Tesla V100 GPUs (and only a modest premium for SXM-enabled host-servers). Nearly all DL applications benefit greatly from the NVLink interface from GPU:GPU; a selection of HPC applications (ex: AMBER) do today.
If you’re running DL frameworks, select Tesla V100 and if possible the SXM-enabled GPUs and servers.
FLOPS vs Real Application Performance
Unless you firmly know your workload correlates, we strongly discourage anyone from making purchasing decisions strictly based upon raw $/FLOP calculations.
While the generalizations above are useful, application performance differs dramatically from any simplistic FLOPS calculation. Device/device bandwidth, host-device bandwidth, GPU memory bandwidth, code maturity, are all equal levers to FLOPS on realized application performance.
Here’s some of NVIDIA’s own application performance testing across some real applications
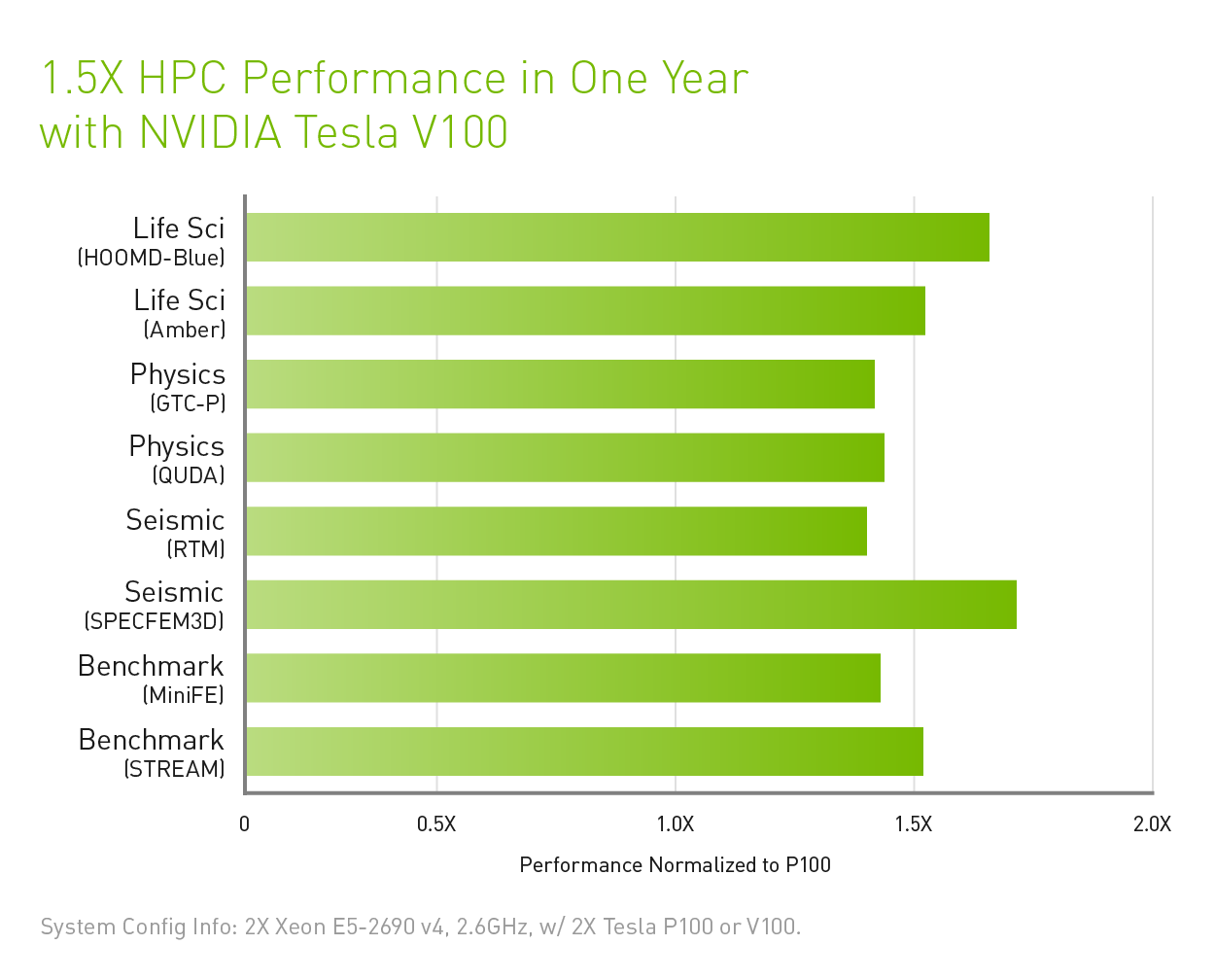
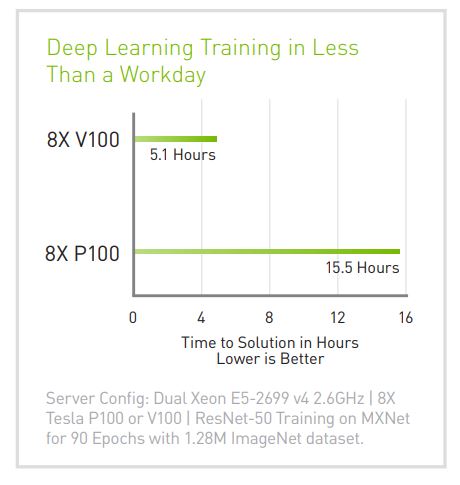
You’ll see that some codes scale similarly to the on-paper FLOPS gains, and others are frankly far more removed.
At the most, use such simplistic FLOPS and price/performance calculations to guide the following higher level decision-making: to help predict new hardware relative to prior testing of FLOPS vs. actual performance, to steer what GPUs to consider, to decide what to purchase for POCs, or as the way to identify appropriate GPUs to remotely test to validate actual application performance.
No one should buy based upon price/performance per FLOP; most should buy based upon price/performance per workload (or basket of workloads).
When Paper Performance + Intuition Collide with Reality
While the above guidelines are helpful, there are still a wide diversity of workloads out there in the field. Apart from testing that steers you to one GPU or another, here’s some good reasons we’ve seen or advised customers to use to make other selections:

- Your application has shown diminishing returns to advances in GPU performance in the past (Tesla P100 might be a price/performance choice)
- Your budget doesn’t allow for even a single Tesla V100 (pick Tesla P100, still great speedups)
- Your budget allows for a server with 2 Tesla P100s, but not 2 Tesla V100s (Pick 2 Tesla P100s vs 1 Tesla V100)
- Your application is GPU memory capacity-bound (pick Tesla V100 32GB)
- There are workload sharing considerations (ex: preferred scheduler only allocates whole GPUs)
- Your application isn’t multi-GPU enabled (pick Tesla V100, the most powerful single GPU)
- Your application is GPU memory bandwidth limited (test it, but potential case for Tesla P100)
Further Resources
You may wish to reference our Comparison of Tesla “Volta” GPUs, which summarizes the technical improvements made in these new GPUs or Tesla V100 GPU Review for more extended discussion.
If you’re looking to see how these GPUs will be deployed in production, read our NVIDIA GPU Clusters page. As always, please feel free to reach out to us if you’d like to get a better understanding of these latest HPC systems and what they can do for you.
