Artificial Intelligence (AI) and, more specifically, Deep Learning (DL) are revolutionizing the way businesses utilize the vast amounts of data they collect and how researchers accelerate their time to discovery. Some of the most significant examples come from the way AI has already impacted life as we know it such as smartphone speech recognition, search engine image classification, and cancer detection in biomedical imaging. Most businesses have collected troves of data or incorporated new avenues to collect data in recent years. Through the innovations of deep learning, that same data can be used to gain insight, make accurate predictions, and pave the path to discovery.
Developing a plan to integrate AI workloads into an existing business infrastructure or research group presents many challenges. However, there are two key elements that will drive the decisions to customizing an AI cluster. First, understanding the types and volumes of data is paramount to beginning to understand the computational requirements of training the neural network. Secondly, understanding the business expectation for time to result is equally important. Each of these factors influence the first and second stages of the AI workload, respectively. Underestimating the data characteristics will result in insufficient computational and infrastructure resources to train the networks in a reasonable timeframe. Moreover, underestimating the value and requirement of time-to-results can fail to deliver ROI to the business or hamper research results.
Below are summaries of the different features of system design that must be evaluated when configuring an AI cluster in 2017.
System Architectures
AI workloads are very similar to HPC workloads in that they require massive computational resources combined with fast and efficient access to giant datasets. Today, there are systems designed to serve the workload of an AI cluster. These systems outlined in sections below generally share similar characteristics: high-performance CPU cores, large-capacity system memory, multiple NVLink-connected GPUs per node, 10G Ethernet, and EDR InfiniBand. However, there are nuanced differences with each platform. Read below for more information about each.
Microway GPU-Accelerated NumberSmashers
Microway demonstrates the value of experience with every GPU cluster deployment. The company’s long history of designing and deploying state of the art GPU clusters for HPC makes our expertise invaluable when custom configuring full-scale, production-ready AI clusters. One of the most common GPU nodes used in our AI offerings is the NumberSmasher 1U with NVLink. The system features dense compute performance in a small footprint, making it a building block for scale-out cluster design. Alternatively, the Octoputer with Single Root Complex offers the most GPUs per system to maximize the total throughput of a single system.
To ensure maximum performance and field reliability, our system integrators test and tune every node built. Clusters, once integrated, undergo total system testing to assure total peak system operability. We offer AI integration services for installation and testing of AI frameworks in addition to the full suite of cluster management utilities and software. Additionally, all Microway systems come complete with Lifetime Technical Support.
To learn more about Microway’s GPU clusters and systems, please visit Tesla GPU clusters.
NVIDIA DGX Systems
NVIDIA’s DGX-1 and DGX Station systems deliver not only dense computational power per system, they also include access to the NVIDIA GPU Cloud and Container Registry. These NVIDIA resources provide optimized container environments for the host of libraries and frameworks typically running on an AI cluster. This allows researchers and data scientists to focus on delivering results instead of worrying about software maintenance and tuning. As an Elite Solutions Provider of NVIDIA products, Microway offers DGX systems as either a full system solution or as part of a custom cluster design.

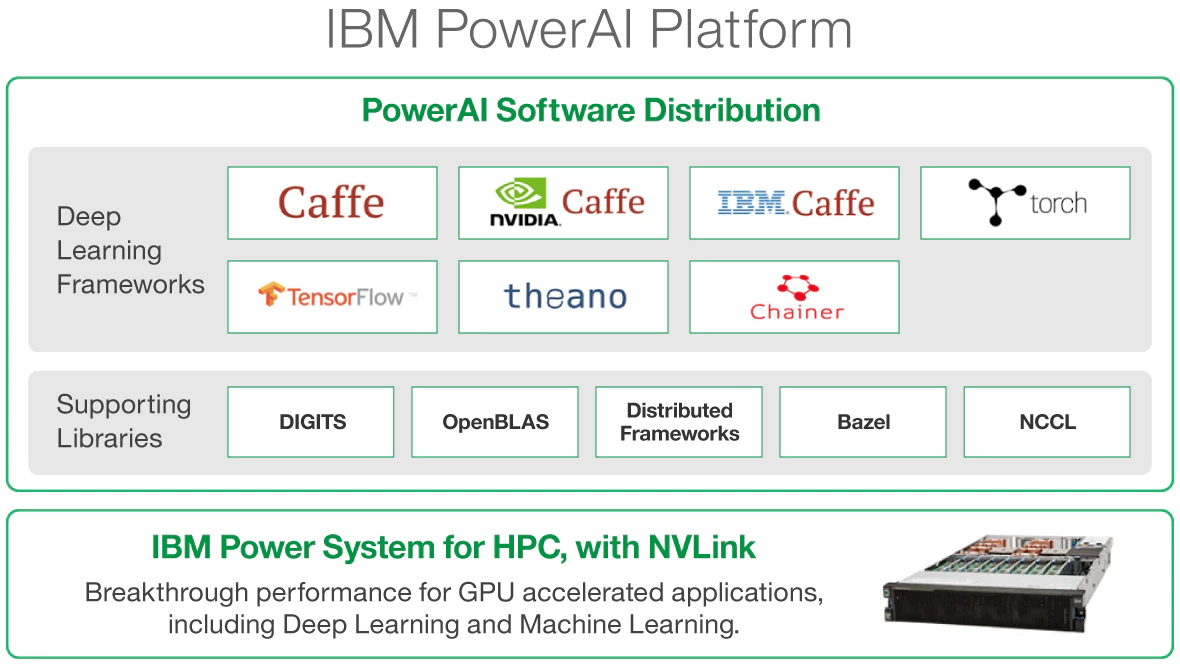
IBM Power Systems with PowerAI
IBM’s commitment to innovative chip and system design for HPC and AI workloads has created a platform for next-generation computing. Through collaboration with NVIDIA, the IBM Power Systems are the only available GPU platforms that integrate NVLink connectivity between the CPU and GPU. IBM’s latest AC922 Power System release delivers 10x the throughput over traditional x86 systems. Additionally, Microway integrates IBM PowerAI to provide faster time to deployment with their optimized software distribution.


Professional vs. Consumer GPUs
NVIDIA GPUs are the primary element to designing a world class AI deployment. In fact, NVIDIA’s commitment to delivering AI to everyone has led them to produce a multi-tiered array of GPU accelerators. Microway’s engineers often face questions about the difference between NVIDIA’s consumer GeForce and professional Tesla GPU accelerators. Although at first glance the higher-end GeForce GPUs seem to mimic the computational capabilities of the professional Tesla products, this is not always the case. Upon further inspection, the differences become quite evident.
When determining which GPU to use, raw performance numbers are typically the first technical specifications to review. In specific regard to AI workloads, a Tesla GPU has up to 1000X the performance of a high end GeForce card running half precision floating point calculations (FP16). The GeForce cards also do not support INT8 instructions used in Deep Learning inferencing. Although it is possible to use consumer GPUs for AI work, it is not recommended for large-scale production deployments. Aside from raw throughput, there are many other features that we outline in our article at the link below.
The price of the consumer cards allows businesses and researchers to understand the potential impact of AI and develop code on single systems without investing in a larger infrastructure. Microway recommends that the use of consumer cards be limited to development workstations during the investigatory and development process.
Our knowledge center provides a detailed article on the differences between Tesla and GeForce.
Training and Inferencing
There is a stark contrast between the resources needed for efficient training versus efficient inferencing. Training neural networks requires significant GPU resources for computation, host system resources for data passing, reliable and fast access to entire datasets, and a network architecture to support it all. The resource requirement for inferencing, however, depends on how the new data will be inferenced in production. Real-time inferencing has a far lower computational requirement because the data is fed to the neural network as it occurs in real time. This is very different from bulk inference where entire new data sets are fed into the neural network at the same time. Also, going back to the beginning, understanding the expectation for time-to-result will likely impact the overall cluster design regardless of inference workload.
Storage Architecture
The type of storage architecture used with an AI cluster can and will have a significant impact on efficiency of the cluster. Although storage can seem a rather nebulous topic, the demands of an AI workload are a mostly known factor. During training, the nodes of the cluster will need access to entire data sets because the data will be accessed often and in succession throughout the training process. Many commercial AI appliances, such as the DGX-1, leverage large high-speed cache volumes in each node for efficiency.
Standard and High-Performance Network File Systems are sufficient for small to medium sized AI cluster deployments. If the nodes have been configured properly to each have sufficient cache space, the file system itself does not need to be exceptionally performant as it is simply there for long-term storage. However, if the nodes do not have enough local cache space for the dataset, the need for performant storage increases. There are component features that can increase the performance of an NFS without moving to a parallel file system, but this is not a common scenario for this workload. The goal should always be to have enough local cache space for optimal performance.
Parallel File Systems are known for their performance and sometimes price. These storage systems should be reserved for larger cluster deployments where it will provide the best benefit per dollar spent.
Network Infrastructure
Deploying the right kind of network infrastructure will reduce bottlenecks and improve the performance of the AI cluster. The guidelines for networking will change depending on the size/type of data passing through the network as well as the nature of the computation. For instance, small text files will not need as much bandwidth as 4K video files, but Deep Learning training requires access to the entire data pool which can saturate the network. Going back to the beginning of this article, understanding data sets will help identify and prevent system bottlenecks. Our experts can help walk you through that analysis.
All GPU cluster deployments, regardless of workload, should utilize a tiered networking system that includes a management network and data traffic network. Management networks are typically a single Gigabit or 10Gb Ethernet link to support system management and IPMI. Data traffic networks, however, can require more network bandwidth to accommodate the increased amount of traffic as well as lower latency for increased efficiency.
Common data networks use either Ethernet (10G/25G/40G/50G) or InfiniBand (200Gb or 100Gb). There are many cases where 10G~50G Ethernet will be sufficient for the file sizes and volume of data passing through the network at the same time. These types of networks are often used in workloads with smaller files sizes such as still images or where computation happens within a single node. They can also be a cost-effective network for a cluster with a small number of nodes.
However, for larger files and/or multi-node GPU computation such as DL training, 100Gb EDR InfiniBand is the network fabric of choice for increased bandwidth and lower latency. InfiniBand enables Peer-to-Peer GPU communication between nodes via Remote Direct Memory Access (RDMA) which can increase the efficiency of the overall system.
To compare network speeds and latencies, please visit Performance Characteristics of Common Network Fabrics
