The new NVIDIA Tesla P100 GPUs are available with both PCI-Express and NVLink connectivity. How do these two types of connectivity compare? This post provides a rundown of NVLink vs PCI-E and explores the benefits of NVIDIA’s new NVLink technology.

Considering the variety of options for Tesla P100 GPUs, you may wish to review our other recent posts:
- Tesla P100 PCI-E GPUs
- Tesla P100 NVLink GPUs (with PCI-E connectivity to the host)
- Tesla P100 NVLink GPUs (with NVLink connectivity to the host) (this post)
Primary considerations when comparing NVLink vs PCI-E
On systems with x86 CPUs (such as Intel Xeon), the connectivity to the GPU is only through PCI-Express (although the GPUs connect to each other through NVLink). On systems with POWER8 CPUs, the connectivity to the GPU is through NVLink (in addition to the NVLink between GPUs).
Nevertheless, the performance characteristics of the GPU itself (GPU cores, GPU memory, etc) do not vary. The Tesla P100 GPU itself will be performing at the same level. It’s the data flow and total system throughput that will determine the final performance for your workload. To review:
- Full NVLink connectivity is only available with IBM POWER8 CPUs (not x86 CPUs)
- GPU-to-GPU NVLink connectivity (without CPU-to-GPU) is available with x86 CPUs
- Internal performance of an NVIDIA Tesla P100 SXM2 GPU will not vary between x86 and POWER8
With that in mind, let’s compare their throughput.
Tesla P100 with NVLink on OpenPOWER
The NVLink connections on Tesla P100 GPUs provide a theoretical peak throughput of 80GB/s (160GB/s bi-directional). However, those links are made up of several bricks, which can be split up to connect to a number of other devices. For example, one GPU might dedicate 40GB/s for a link to a CPU and 40GB/s for a link to a nearby GPU.
Device <-> Device NVLink Performance
Below is the output from NVIDIA’s GPU peer-to-peer (P2P) utility, which is included with CUDA 8.0. The results summarize the throughput (in gigabytes per second) and latency (in microseconds) when sending messages between pairs of Tesla P100 GPUs in our OperPOWER system.
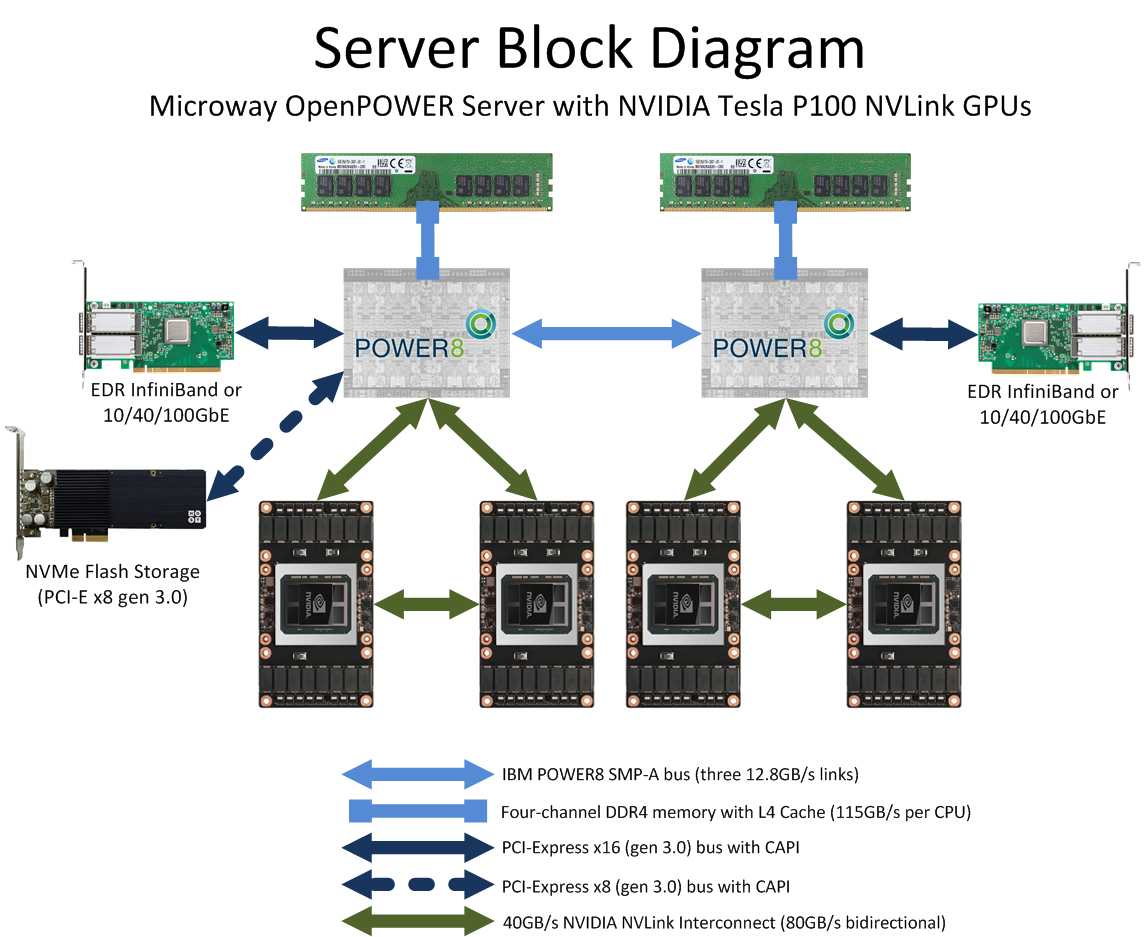
It’s important to understand that the test below was run on a system with four Tesla GPUs. On each GPU, the available 80GB/s bandwidth was divided in half. One link goes to a POWER8 CPU and one link goes to the adjacent P100 GPU (see diagram below).
[P2P (Peer-to-Peer) GPU Bandwidth Latency Test]
Device: 0, Tesla P100-SXM2-16GB, pciBusID: 1, pciDeviceID: 0, pciDomainID:2
Device: 1, Tesla P100-SXM2-16GB, pciBusID: 1, pciDeviceID: 0, pciDomainID:3
Device: 2, Tesla P100-SXM2-16GB, pciBusID: 1, pciDeviceID: 0, pciDomainID:a
Device: 3, Tesla P100-SXM2-16GB, pciBusID: 1, pciDeviceID: 0, pciDomainID:b
...
Unidirectional P2P=Enabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3
0 457.93 35.30 20.37 20.40
1 35.30 454.78 20.16 20.14
2 20.19 20.16 454.56 35.29
3 18.36 18.42 35.29 454.07
...
P2P=Enabled Latency Matrix (us)
D\D 0 1 2 3
0 4.99 7.92 15.56 15.43
1 8.06 5.00 15.40 15.40
2 15.47 15.52 5.04 8.07
3 15.43 15.49 8.04 4.97
As the results show, each 40GB/s Tesla P100 NVLink will provide ~35GB/s in practice. Communications between GPUs on a remote CPU offer throughput of ~20GB/s. Latency between GPUs is 8~16 microseconds. The results were gathered on our 2U OpenPOWER GPU server with Tesla P100 NVLink GPUs, which is available to benchmark in our Test Drive cluster. The architectural design of this particular platform is:
Device <-> Device PCI-E Performance
A similar test, run on GPUs connected by standard PCI-Express, will result in the following performance:
Unidirectional P2P=Enabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3
0 452.19 10.19 10.73 10.74
1 10.19 450.04 10.76 10.75
2 10.91 10.90 450.94 10.21
3 10.90 10.91 10.18 450.95
...
P2P=Enabled Latency Matrix (us)
D\D 0 1 2 3
0 3.22 7.86 16.90 17.05
1 7.85 3.21 17.08 17.22
2 16.32 16.37 3.07 7.85
3 16.26 16.35 7.84 3.07
The latencies between GPUs are about the same (although there is a larger latency when traveling to GPUs on remote CPUs. However, transfer bandwidth is significantly higher for NVlink vs PCI-E (two to three times higher). This increased throughput gives NVLink an advantage for fine-grained applications and others which send data between GPUs.
NVLink vs PCI-E: Host <-> Device Performance
CPU-to-GPU data transfers occur whenever data must be transferred into or out of the GPU. These are typically called host-to-device and device-to-host transfers. Traditional systems with x86 CPUs are only able to communicate with the GPUs over PCI-Express, which provides lower throughput. Our OpenPOWER systems provide full NVLink connectivity to the GPUs. Here’s the achieved performance:
Host <-> Device across NVLink
[root@openpower8 ~]# ./bandwidthTest --memory=pinned --device=0 [CUDA Bandwidth Test] - Starting... Running on... Device 0: Tesla P100-SXM2-16GB Quick Mode Host to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 33236.9 Device to Host Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 32322.6 Device to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 448515.9 Result = PASS
Host <-> Device across PCI-E
A similar test, run on an x86 system with GPUs connected by PCI-Express, will result in the following performance:
... Device 0: Tesla P100-PCIE-16GB Quick Mode Host to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 11658.4 Device to Host Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 12882.0 Device to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 446125.2
Just as with the GPU-to-GPU transfers, we see that NVLink enables much faster performance. Remember that this type of transfer occurs whenever you load a dataset into main memory and then process some of that data on the GPUs. These transfer times are often a factor in overall application performance, so a 3X speedup is welcome. This increased performance may also enable applications which were previously too data-movement-intensive.
Finally, consider that NVIDIA CUDA 8.0 (together with the Tesla P100 GPUs) allows for fully Unified Memory. You will be able to load datasets larger than GPU memory and let the system automatically manage data movement. In other words, the size of GPU memory no longer limits the size of your jobs. On such runs, having a wider pipe between CPU and GPU memory is of immense importance.
NVIDIA deviceQuery on OpenPOWER server with Tesla P100 GPUs and NVLink
Each new GPU generation brings tweaks to the design. The output below, from the CUDA 8.0 SDK samples, shows additional details of the architecture and capabilities of the “Pascal” Tesla P100 GPU accelerators with NVLink. Take note of the new Compute Capability 6.0, which is what you’ll want to target if you’re compiling your own CUDA code. Also note that in this platform there are three DMA copy engines per GPU.
deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 4 CUDA Capable device(s)
Device 0: "Tesla P100-SXM2-16GB"
CUDA Driver Version / Runtime Version 8.0 / 8.0
CUDA Capability Major/Minor version number: 6.0
Total amount of global memory: 16281 MBytes (17071669248 bytes)
(56) Multiprocessors, ( 64) CUDA Cores/MP: 3584 CUDA Cores
GPU Max Clock rate: 1481 MHz (1.48 GHz)
Memory Clock rate: 715 Mhz
Memory Bus Width: 4096-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 2 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
[...]
> Peer access from Tesla P100-SXM2-16GB (GPU0) -> Tesla P100-SXM2-16GB (GPU1) : Yes
> Peer access from Tesla P100-SXM2-16GB (GPU0) -> Tesla P100-SXM2-16GB (GPU2) : No
> Peer access from Tesla P100-SXM2-16GB (GPU0) -> Tesla P100-SXM2-16GB (GPU3) : No
> Peer access from Tesla P100-SXM2-16GB (GPU1) -> Tesla P100-SXM2-16GB (GPU0) : Yes
> Peer access from Tesla P100-SXM2-16GB (GPU1) -> Tesla P100-SXM2-16GB (GPU2) : No
> Peer access from Tesla P100-SXM2-16GB (GPU1) -> Tesla P100-SXM2-16GB (GPU3) : No
> Peer access from Tesla P100-SXM2-16GB (GPU2) -> Tesla P100-SXM2-16GB (GPU0) : No
> Peer access from Tesla P100-SXM2-16GB (GPU2) -> Tesla P100-SXM2-16GB (GPU1) : No
> Peer access from Tesla P100-SXM2-16GB (GPU2) -> Tesla P100-SXM2-16GB (GPU3) : Yes
> Peer access from Tesla P100-SXM2-16GB (GPU3) -> Tesla P100-SXM2-16GB (GPU0) : No
> Peer access from Tesla P100-SXM2-16GB (GPU3) -> Tesla P100-SXM2-16GB (GPU1) : No
> Peer access from Tesla P100-SXM2-16GB (GPU3) -> Tesla P100-SXM2-16GB (GPU2) : Yes
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 4, Device0 = Tesla P100-SXM2-16GB, Device1 = Tesla P100-SXM2-16GB, Device2 = Tesla P100-SXM2-16GB, Device3 = Tesla P100-SXM2-16GB
Result = PASS
How to move forward – GPU systems with Host-to-Device NVLink
Due to the new high-speed NVLink connection, there is only one server on the market with both Host-to-Device and Device-to-Device NVLink connectivity. This system, leveraging IBM’s POWER8 CPUs and innovation from the OpenPOWER foundation (including NVIDIA and Mellanox), began shipments in fall 2016. Please contact us to learn more, or read about this OpenPOWER server. Academic discounts are available.
To learn more about the available NVIDIA Tesla “Pascal” GPUs and to compare with other versions of the Tesla product line, please review our “Pascal” Tesla GPU knowledge center article:
If you’re thinking about using GPUs for the first time, please consider getting in touch with us. We’ve been implementing GPU-accelerated systems for nearly a decade and have the expertise to help make your project a success!
