Sources of CPU benchmarks, used for estimating performance on similar workloads, have been available throughout the course of CPU development.For example, the Standard Performance Evaluation Corporation has compiled a large set of applications benchmarks, running on a variety of CPUs, across a multitude of systems. There are certainly benchmarks for GPUs, but only during the past year has an organized set of deep learning benchmarks been published. Called DeepMarks, these deep learning benchmarks are available to all developers who want to get a sense of how their application might perform across various deep learning frameworks.
The benchmarking scripts used for the DeepMarks study are published at GitHub. The original DeepMarks study was run on a Titan X GPU (Maxwell microarchitecture), having 12GB of onboard video memory. Here we will examine the performance of several deep learning frameworks on a variety of Tesla GPUs, including the Tesla P100 16GB PCIe, Tesla K80, and Tesla M40 12GB GPUs.
Data from Deep Learning Benchmarks
The deep learning frameworks covered in this benchmark study are TensorFlow, Caffe, Torch, and Theano. All deep learning benchmarks were single-GPU runs. The benchmarking scripts used in this study are the same as those found at DeepMarks. DeepMarks runs a series of benchmarking scripts which report the time required for a framework to process one forward propagation step, plus one backpropagation step. The sum of both comprises one training iteration. The times reported are the times required for one training iteration per batch, in milliseconds.
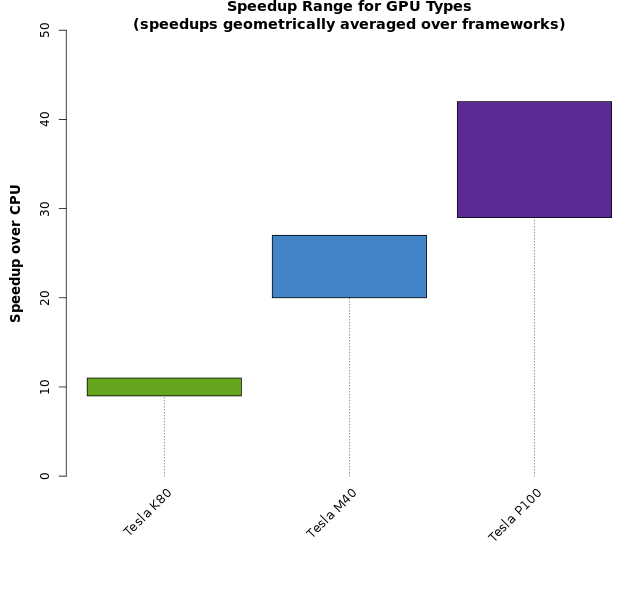
To start, we ran CPU-only trainings of each neural network. We then ran the same trainings on each type of GPU. The plot below depicts the ranges of speedup that were obtained via GPU acceleration.
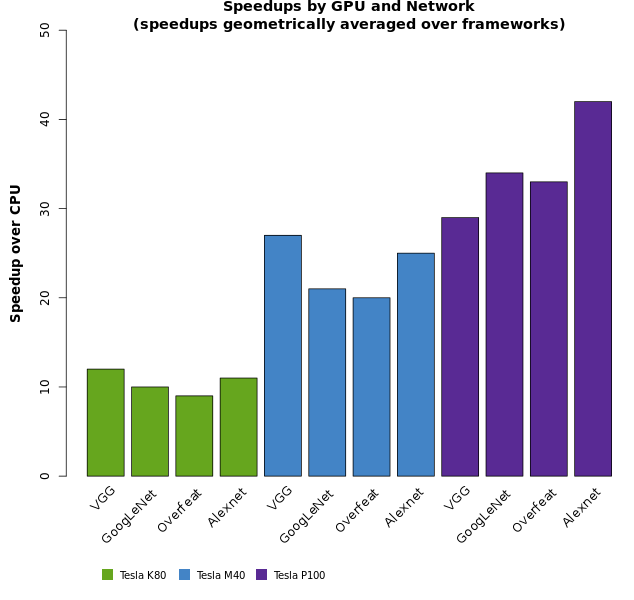
If we expand the plot and show the speedups for the different types of neural networks, we see that some types of networks undergo a larger speedup than others.
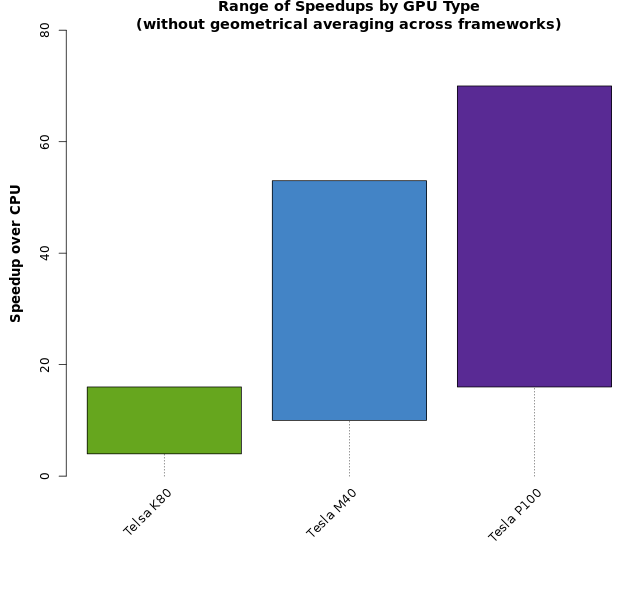
If we take a step back and look at the ranges of speedups the GPUs provide, there is a fairly wide range of speedup. The plot below shows the full range of speedups measured (without geometrically averaging across the various deep learning frameworks). Note that the ranges are widened and become overlapped.
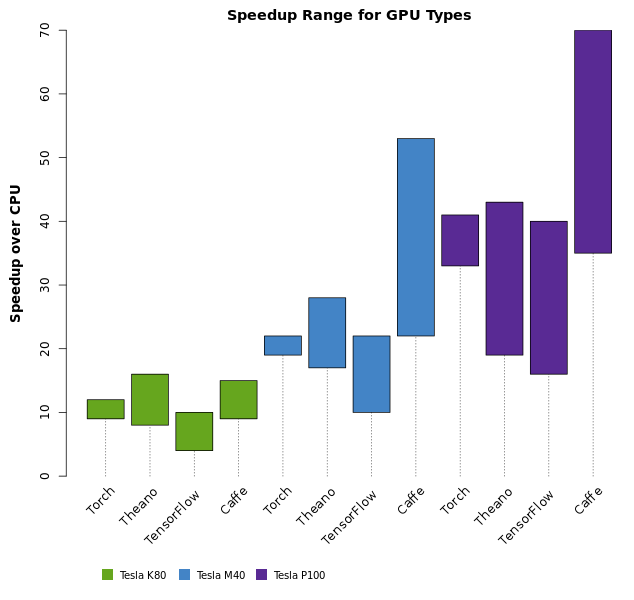
We believe the ranges resulting from geometric averaging across frameworks (as shown in Figure 1) results in narrower distributions and appears to be a more accurate quality measure than is shown in Figure 3. However, it is instructive to expand the plot from Figure 3 to show each deep learning framework. Those ranges, as shown below, demonstrate that your neural network training time will strongly depend upon which deep learning framework you select.
As shown in all four plots above, the Tesla P100 PCIe GPU provides the fastest speedups for neural network training. With that in mind, the plot below shows the raw training times for each type of neural network on each of the four deep learning frameworks.
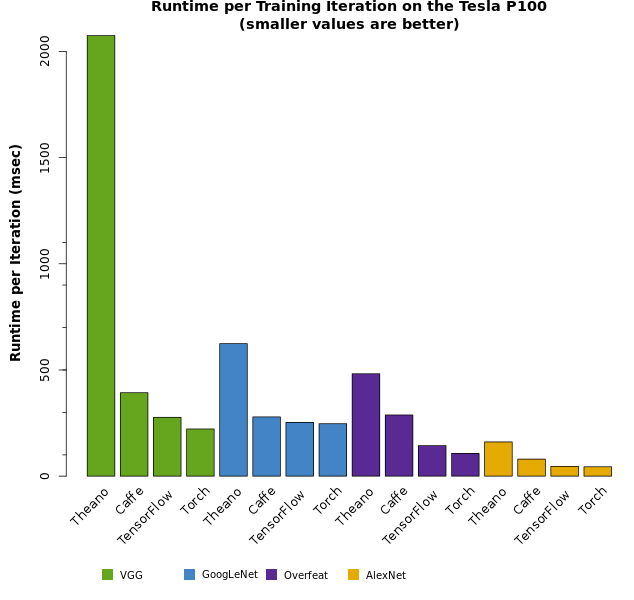
We provide more discussion below. For reference, we have listed the measurements from each set of tests.
Tesla P100 16GB PCIe Benchmark Results
| AlexNet | Overfeat | GoogLeNet | VGG (ver.a) | Speedup Over CPU | |
|---|---|---|---|---|---|
| Caffe | 80 | 288 | 279 | 393 | (35x ~ 70x speedups) |
| TensorFlow | 46 | 144 | 253 | 277 | (16x ~ 40x speedups) |
| Theano | 161 | 482 | 624 | 2075 | (19x ~ 43x speedups) |
| cuDNN-fp32 (Torch) | 44 | 107 | 247 | 222 | (33x ~ 41x speedups) |
| geometric average over frameworks | 71 | 215 | 331 | 473 | (29x ~ 42x speedups) |
Table 1: Benchmarks were run on a single Tesla P100 16GB PCIe GPU. Times reported are in msec per batch. The batch size for all training iterations measured for runtime in this study is 128, except for VGG net, which uses a batch size of 64.
Tesla K80 Benchmark Results
| AlexNet | Overfeat | GoogLeNet | VGG (ver.a) | Speedup Over CPU | |
|---|---|---|---|---|---|
| Caffe | 365 | 1,187 | 1,236 | 1,747 | (9x ~ 15x speedups) |
| TensorFlow | 181 | 622 | 979 | 1,104 | (4x ~ 10x speedups) |
| Theano | 515 | 1,716 | 1,793 | — | (8x ~ 16x speedups) |
| cuDNN-fp32 (Torch) | 171 | 379 | 914 | 743 | (9x ~ 12x speedups) |
| geometric average over frameworks | 276 | 832 | 1,187 | 1,127 | (9x ~ 11x speedups) |
Table 2: Benchmarks were run on a single Tesla K80 GPU chip. Times reported are in msec per batch.
Tesla M40 Benchmark Results
| AlexNet | Overfeat | GoogLeNet | VGG (ver.a) | Speedup Over CPU | |
|---|---|---|---|---|---|
| Caffe | 128 | 448 | 468 | 637 | (22x ~ 53x speedups) |
| TensorFlow | 82 | 273 | 418 | 498 | (10x ~ 22x speedups) |
| Theano | 245 | 786 | 963 | — | (17x ~ 28x speedups) |
| cuDNN-fp32 (Torch) | 79 | 182 | 433 | 400 | (19x ~ 22x speedups) |
| geometric average over frameworks | 119 | 364 | 534 | 506 | (20x ~ 27x speedups) |
Table 3: Benchmarks were run on a single Tesla M40 GPU. Times reported are in msec per batch.
CPU-only Benchmark Results
| AlexNet | Overfeat | GoogLeNet | VGG (ver.a) | |
|---|---|---|---|---|
| Caffe | 4,529 | 10,350 | 18,545 | 14,010 |
| TensorFlow | 1,823 | 5,275 | 4,018 | 7,341 |
| Theano | 5,275 | 13,579 | 26,829 | 38,687 |
| cuDNN-fp32 (Torch) | 1,838 | 3,604 | 8,234 | 9,166 |
| geometric average over frameworks | 2,991 | 7,190 | 11,326 | 13,819 |
Table 4: Benchmarks were run on dual Xeon E5-2690v4 processors in a system with 256GB RAM. Times reported are in msec per batch.
Discussion
When geometric averaging is applied across framework runtimes, a range of speedup values is derived for each GPU, as shown in Figure 1.CPU times are also averaged geometrically across framework type.These results indicate that the greatest speedups are realized with the Tesla P100, with the Tesla M40 ranking second, and the Tesla K80 yielding the lowest speedup factors.Figure 2 shows the range of speedup values by network architecture, uncollapsed from the ranges shown in Figure 1.
The speedup ranges for runtimes not geometrically averaged across frameworks are shown in Figure 3.Here the set of all runtimes corresponding to each framework/network pair is considered when determining the range of speedups for each GPU type.Figure 4 shows the speedup ranges by framework, uncollapsed from the ranges shown in figure 3.The degree of overlap in Figure 3 suggests that geometric averaging across framework type yields a better measure of GPU performance, with more narrow and distinct ranges resulting for each GPU type, as shown in Figure 1.
The greatest speedups were observed when comparing Caffe forward+backpropagation runtime to CPU runtime, when solving the GoogLeNet network model. Caffe generally showed speedups larger than any other framework for this comparison, ranging from 35x to ~70x (see Figure 4 and Table 1). Despite the higher speedups, Caffe does not turn out to be the best performing framework on these benchmarks (see Figure 5).When comparing runtimes on the Tesla P100, Torch performs best and has the shortest runtimes (see Figure 5).Note that although the VGG net tends to be the slowest of all, it does train faster then GooLeNet when run on the Torch framework (see Figure 5).
The data show that Theano and TensorFlow display similar speedups on GPUs (see Figure 4).Despite the fact that Theano sometimes has larger speedups than Torch, Torch and TensorFlow outperform Theano.While Torch and TensorFlow yield similar performance, Torch performs slightly better with most network / GPU combinations.However, TensorFlow outperforms Torch in most cases for CPU-only training (see Table 4).
Theano is outperformed by all other frameworks, across all benchmark measurements and devices (see Tables 1 – 4). Figure 5 shows the large runtimes for Theano compared to other frameworks run on the Tesla P100.It should be noted that since VGG net was run with a batch size of only 64, compared to 128 with all other network architectures, the runtimes can sometimes be faster with VGG net, than with GoogLeNet.See, for example, the runtimes for Torch, on GoogLeNet, compared to VGG net, across all GPU devices (Tables 1 – 3).
Deep Learning Benchmark Conclusions
The single-GPU benchmark results show that speedups over CPU increase from Tesla K80, to Tesla M40, and finally to Tesla P100, which yields the greatest speedups (Table 5, Figure 1) and fastest runtimes (Table 6).
Range of Speedups, by GPU type
| Tesla P100 16GB PCIe | Tesla M40 12GB | Tesla K80 |
|---|---|---|
| 19x ~ 70x | 10x ~ 53x | 4x ~ 16x |
Table 5: Measured speedups for running various deep learning frameworks on GPUs (see Table 1)
Fastest Runtime for VGG net, by GPU type
| Tesla P100 16GB PCIe | Tesla M40 12GB | Tesla K80 |
|---|---|---|
| 222 | 408 | 743 |
Table 6: Absolute best runtimes (msec / batch) across all frameworks for VGG net (ver. a). The Torch framework provides the best VGG runtimes, across all GPU types.
The results show that of the tested GPUs, Tesla P100 16GB PCIe yields the absolute best runtime, and also offers the best speedup over CPU-only runs. Regardless of which deep learning framework you prefer, these GPUs offer valuable performance boosts.
Benchmark Setup
Microway’s GPU Test Drive compute nodes were used in this study. Each is configured with 256GB of system memory and dual 14-core Intel Xeon E5-2690v4 processors (with a base frequency of 2.6GHz and a Turbo Boost frequency of 3.5GHz). Identical benchmark workloads were run on the Tesla P100 16GB PCIe, Tesla K80, and Tesla M40 GPUs. The batch size is 128 for all runtimes reported, except for VGG net (which uses a batch size of 64).All deep learning frameworks were linked to the NVIDIA cuDNN library (v5.1), instead of their own native deep network libraries.This is because linking to cuDNN yields better performance than using the native library of each framework.
When running benchmarks of Theano, slightly better runtimes resulted when CNMeM, a CUDA memory manager, is used to manage the GPU’s memory. By setting lib.cnmem=0.95, the GPU device will have CNMeM manage 95% of its memory:
THEANO_FLAGS='floatX=float32,device=gpu0,lib.cnmem=0.95,allow_gc=True' python ...
Notes on Tesla M40 versus Tesla K80
The data demonstrate that Tesla M40 outperforms Tesla K80. When geometrically averaging runtimes across frameworks, the speedup of the Tesla K80 ranges from 9x to 11x, while for the Tesla M40, speedups range from 20x to 27x.The same relationship exists when comparing ranges without geometric averaging.This result is expected, considering that the Tesla K80 card consists of two separate GK210 GPU chips (connected by a PCIe switch on the GPU card).Since the benchmarks here were run on single GPU chips, the benchmarks reflect only half the throughput possible on a Tesla K80 GPU. If running a perfectly parallel job, or two separate jobs, the Tesla K80 should be expected to approach the throughput of a Tesla M40.
Singularity Containers
![]() Singularity is a new type of container designed specifically for HPC environments. Singularity enables the user to define an environment within the container, which might include customized deep learning frameworks, NVIDIA device drivers, and the CUDA 8.0 toolkit. The user can copy and transport this container as a single file, bringing their customized environment to a different machine where the host OS and base hardware may be completely different. The container will process the workflow within it to execute in the host’s OS environment, just as it does in its internal container environment. The workflow is pre-defined inside of the container, including and necessary library files, packages, configuration files, environment variables, and so on.
Singularity is a new type of container designed specifically for HPC environments. Singularity enables the user to define an environment within the container, which might include customized deep learning frameworks, NVIDIA device drivers, and the CUDA 8.0 toolkit. The user can copy and transport this container as a single file, bringing their customized environment to a different machine where the host OS and base hardware may be completely different. The container will process the workflow within it to execute in the host’s OS environment, just as it does in its internal container environment. The workflow is pre-defined inside of the container, including and necessary library files, packages, configuration files, environment variables, and so on.
In order to facilitate benchmarking of four different deep learning frameworks, Singularity containers were created separately for Caffe, TensorFlow, Theano, and Torch. Given its simplicity and powerful capabilities, you should expect to hear more about Singularity soon.
References
DeepMarks
Deep Learning Benchmarks published on GitHub
Singularity
Containers for Full User Control of Environment
Alexnet
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012.
Overfeat
Sermanet, Pierre, et al. “Overfeat: Integrated recognition, localization and detection using convolutional networks.” arXiv preprint arXiv:1312.6229 (2013).
GoogLeNet
Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
VGG Net
Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.”arXiv preprint arXiv:1409.1556 (2014).
