At Microway we design a lot of GPU computing systems. One of the strengths of GPU-compute is the flexibility PCI-Express bus. Assuming the server has appropriate power and thermals, it enables us to attach GPUs with no special interface modifications. We can even swap to new GPUs under many circumstances. However, we encounter a lot of misinformation about PCI-Express and GPUs. Here are a number of myths about PCI-E:
1. PCI-Express is controlled through the chipset
No longer in modern Intel CPU-based platforms. Beginning with the Sandy Bridge CPU architecture in 2012 (Xeon E5 series CPUs, Xeon E3 series CPUs, Core i7-2xxx and newer) Intel integrated the PCI-Express controller into the the CPU die itself. Bringing PCI-Express onto the CPU die came with a substantial latency benefit. This was a major change in platform design, and Intel coupled it with the addition of PCI-Express Gen3 support.
AMD Opteron 6300/4300 CPUs are still the exception: PCI-Express is delivered only through the AMD SR56xx chipset (PCI-E Gen2 only) for these platforms. They will slightly underperform competing Intel Xeon platforms when paired with PCI-Express Gen2 GPUs (Tesla K20/K20X) due to the latency differential. Opteron 6300/4300 CPUs will substantially underperform competing Xeon platforms when PCI-Express Gen3 GPUs are installed.
2. A host system with the newest Intel CPU architecture always delivers optimal performance
Not always true. Intel tends to launch its newest CPU architectures on it’s lowest end CPU products first. Once they are proven in lower end applications, the architecture migrates up to higher end segments months or even years later. The problem? The lowest end, newest architecture CPUs can feature the least number of PCI-Express lanes per socket:
| CPU | Core i7-5xxx? | Xeon E3-1200v3/Core i7-47xx/48xx | Xeon E5-1600v3, Core i7 58xx/59xx | Xeon E5-2400v2 | Xeon E5-2600v3 |
| CPU Socket | Likely Socket 1150 | Socket 1150 | Socket 2011-3/R3 | Socket 1356 | Socket 2011-3/R3 |
| CPU Core Architecture | Broadwell | Haswell | Haswell | Ivy Bridge | Haswell |
| Launch Date | 2015 | Q2 2013 | Q3 2014 | Q1 2014 | Q3 2014 |
| PCI-Express Lanes Per Motherboard | Likely 16 Gen3 | 16 Gen3 | 40 Gen3 (Xeon) 28-40 Gen3 (Core i7) | 48 Gen3 (both CPUs populated) | 80 Gen3 (both CPUs populated) |
Socket 1150 CPUs debuted in mid-2013 and were the only offering with the latest and greatest Haswell architecture for over a year; however, the CPUs available only delivered 16 PCI-Express Gen3 lanes per socket. It was tempting for some users to outfit a system with a modestly priced (and “latest”) Core i7-4700 series “Haswell” CPU during this period. However, this choice could have fundamentally hindered application performance. We’ll see this again when Intel debuts Broadwell for the same socket in 2015.
3. The least expensive host system possible is best when paired with multiple GPUs
Not necessarily and in many cases certainly not. It all comes down to how your application works, how long execution time is, and whether PCI Express transfers are happening throughout. An attempt at small cost savings could have big consequences. Here’s a few examples that counter this myth:
a. Applications running entirely on GPUs with many device-to-device transfers
Your application may be performing almost all of its work on the GPUs and orchestrating constant CUDA device-to-device transfers throughout its run. But a host motherboard and CPU with insufficient PCI-Express lanes may not allow full bandwidth transfers between the GPUs, and that could cripple your job performance.
Many inexpensive Socket 1150 motherboards (max 16 PCI-E lanes) have this issue: install 2 GPUs into what appear as x16 slots, and both operate as x8 links electrically. The forced operation at x8 speeds means that a maximum of half the optimal bandwidth is available for your device-to-device transfers. A capable PCI-Express switch may change the game for your performance in this situation.
b. Applications with extremely short execution time on each GPU
In this case, the data transfer may be the largest piece of total job execution time. If you purchase a low-end CPU without sufficient PCI-Express lanes (and bandwidth) to serve simultaneous transfers to/from all your GPUs, the contention will result in poor application performance.
c. Applications constantly streaming data into and out of the GPU
The classic example here is video/signals processing. If you have a constant stream of HD video or signals data being processed by the GPU in real-time, restricting the size of the pipe to your processing devices (GPUs) is a poor design decision.
I don’t know if any of the above fit me…
If you are unable to analyze your job, we do have some reluctant secondary recommendations. The least expensive CPU configuration providing enough lanes for PCI-Express x16 links to all your GPUs is in our experience the safest purchase. An inexpensive CPU SKU in a specific CPU/platform series (ex: no need to purchase an E5-2690v3 CPU vs. E5-2620v3) is fine if you don’t need fast CPU performance. There are very notable exceptions.
4. PCI-Express switches always mean poor application performance
This myth is very common. In reality performance highly application dependent, and sometimes switches yield superior performance.
Where switching matters
There’s no question that PLX Switches have capacity constraints: 16 PCI-E lanes are nearly always driving 2-4 PCI-Express x16 devices. But PLX switching also has one critical advantage: it fools each device into believing it has a full x16 link present, and it will deliver all 16 lanes of bandwidth to a device if available upstream. 2-4 GPUs attached to a single PLX switch @ PCI-E x16 links will nearly always outperform 2-4 GPUs operating at PCI-E x8 speeds without one.
Furthermore, if you hide latency with staggered CUDA Host-Device transfers, the benefits of a denser compute platform (no MPI coding) could far outweigh the PCI- E bandwidth constraints. First, profile your code to learn more about it. Then optimize your transfers for the architecture.
Superior Performance in the Right Situation
In certain cases PLX switches deliver superior performance or additional features. A few examples:
a. In 2:1 configurations utilizing device-device transfers, full bandwidth is available between neighboring devices. AMBER is a great example of an application where this of strong benefit.
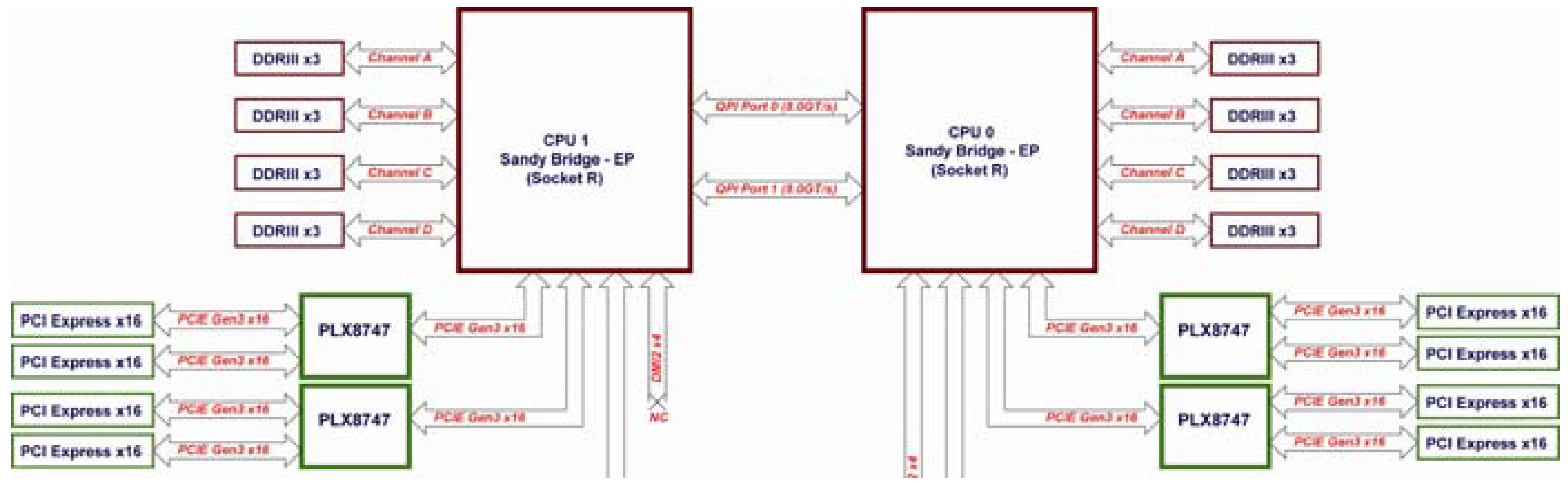
b. Next, in applications leveraging GPU Direct RDMA, switches deliver superior performance. This feature enables a direct transfer between GPU and another device (typically an IB adapter).
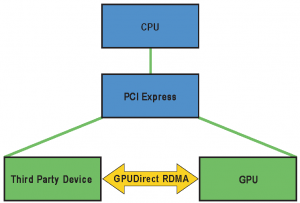
See this presentation for more information on this feature.
c. For multi-GPU configurations where maximum device-device bandwidth between pairs of GPUs at once is of paramount importance, 2 PCI-E switches off of a single socket are likely to offer higher performance vs. an unswitched dual socket configuration. This is due to the added latency and bandwidth constraint of a QPI-hop from CPU0 to CPU1 in a dual socket configuration. Our friends at Cirrascale have explored this bandwidth challenge skillfully.
d. For 4-GPU configurations where maximum device-device bandwidth between all GPUs at once is of paramount importance and host-device bandwidth is not, 1 switch off of single socket may be even better.
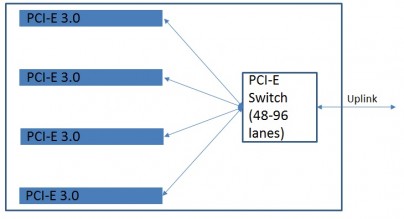
4:1 designs with an appropriate switch offer full bandwidth device-device transfers for 48-96 total PCI-E lanes (including uplink lanes) on the same PCI-E tree. This is impossible with any switchless configuration, and it provides maximum bandwidth for P2P transfers.
However, please don’t assume you can find your ideal PCI-E switch configuration for sale today. Switches are embedded down on motherboards and designs take years to make it to market. For example, we have yet to see many devices with PEX 8796 switch come to market.
Switching is…complex
We’re just starting to see data honestly assessing switched performance in the marketplace. What happens to a particular application’s performance if you sacrifice host-device for device-device bandwidth by pairing a CPU with weak PCI-E I/O capability with a healthy PCI-E switch? Is your total runtime faster? On which applications? How about a configuration that has no switch and simply restricts bandwidth? Does either save you much in total system cost?
Studies of ARM + GPU platform performance (switched and unswitched) and the availability of more platforms with single-socket x86 CPUs + PCI-E switches are starting to tell us more. We’re excited to see the data, but we treat these dilemmas very conservatively until someone can prove to us that restricted bandwidth to the host will result in superior performance for an application.
Concluding thoughts
No one said GPU computing was easy. Understanding your application’s behavior during runs is critical to designing the proper system to run it. Use resource monitors, profilers, and any tool you can to assist. We have a whole blog post series that may help you. Take a GPU Test Drive with Microway to verify.
We encourage you to enlist an expert to help design your system once you know. Complete information about your application’s behavior ensures we can design the system that will perform best for you. As an end-user, you realize a system that is ready to do useful work immediately after delivery. This ensures you get the most complete value out of your hardware purchase.
Finally, we have guidance for when you are in doubt or when you have no data. In this case we recommend any Xeon E5-1600v3 or Xeon E5-2600v3 CPU: they deliver the most PCI-E lanes per socket (40). It’s one of the most robust configurations that keeps you out of trouble. Still, only comprehensive testing will determine the choice with the absolute best price-performance calculation for you. Understand these myths, test your code, let us guide you, and you will procure the best system for your needs!
