This post is Topic #3 (post 3) in our series Parallel Code: Maximizing your Performance Potential.
Many applications contain algorithms which make use of multi-dimensional arrays (or matrices). For cases where threads need to index the higher dimensions of the array, strided accesses can’t really be avoided. In cases where strided access is actually avoidable, every effort to avoid accesses with a stride greater than one should be taken.
So all this advice is great and all, but I’m sure you’re wondering “What actually is strided memory access?” The following example will illustrate this phenomenon and outline its effect on the effective bandwidth:
__global__ void strideExample (float *outputData, float *inputData, int stride=2)
{
int index = (blockIdx.x * blockDim.x + threadIdx.x) * stride;
outputData[index] = inputData[index];
}
In the above code, threads within a warp access data words in memory with a stride of 2. This leads to a load of two L1 cache lines per warp. The actual accessing of the memory is shown below.
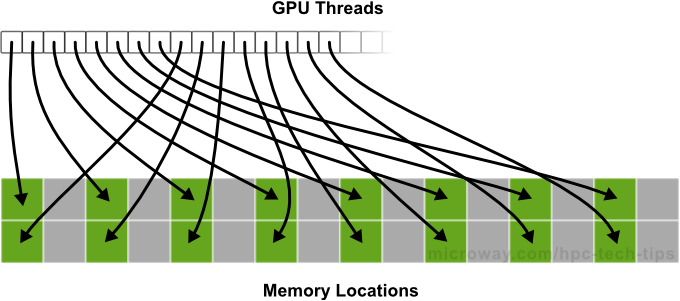
Accesses with a stride of 2 result in a 50% load/store efficiency (shown above), since half of the elements involved in the transaction are not used (becoming wasted bandwidth). As the stride increases, the effective bandwidth decreases until there is a single cache line for each of the threads in a warp (wow, that’s a lot of lost performance!).
Strided accesses can debilitate performance of even the most optimized algorithms. For large strides, the effective bandwidth is poor, regardless of the architecture of compute capability version. Intuitively, this makes sense. When concurrent threads are simultaneously accessing data located in memory addresses that are far apart in the physical memory, the accesses cannot be combined. For these types of situations, you absolutely must not use global memory if you wish to realize any sort of performance gain from your application for accesses with a stride greater than 1. In cases where you are stuck with strided memory accesses, you must ensure that as much data as possible is used from each cache line fetching operation.
So, if I haven’t made it clear enough: if you can avoid global memory, you should. In my personal experiences programming with CUDA, you really can’t go wrong if you intelligently make use of shared memory. With the exception of bank conflicts (discussed in Shared Memory Optimization), you don’t suffer the painful penalties that accompany global memory usage when you have non-sequential memory accesses, or misaligned accesses by warps in shared memory.
For those of us who are more advanced, if you can make use of registers without register pressure or read-after-write dependencies, you should. I briefly discussed register memory in previous posts, but feel that it warrants a bit more discussion here.
Shared memory allows communications between threads, which is very convenient. However, for those of us looking to squeeze out every last drop of performance from our applications, you really need to make use of registers when you can. Think of it this way – shared memory is kind of the “jack of all trades” memory. It’s suitable for “most” applications and operations, but for register operations (without read-after-write issues) there is no comparison. Typically, register access consumes zero extra clock cycles per instruction. While this lack of processing latency makes register memory very appealing, read-after-write dependencies have a latency of roughly 24 clock cycles. When such a dependency appears in a loop of code, this latency will add up very quickly.
The only other downside of register memory is called register pressure. Register pressure occurs when there are just simply not enough registers for a given task. Although every multiprocessor in a GPU contains literally thousands of 32 bit registers, these get partitioned amongst concurrent threads. You can set the maximum number of registers that can be allocated (by the compiler) via the command line.
To summarize, when you’re developing your algorithms and applications you really need to be aware of how you’re making use of memory:
- Global memory is great for beginner programmers, as it drastically simplifies coding for those who aren’t skilled or experienced in regards to CUDA programming. Performance will be lower.
- If you aren’t needing to squeeze out every drop of performance, shared memory can take you to where you need to be. The benefits of thread-to-thread communications within a warp makes many algorithms easier to code and implement, making shared memory a very attractive option.
- Register memory is the fastest, but a little more tricky. There are hard limits to what you can do with register memory, but if what your algorithm requires fits inside those confines, then definitely make use of registers.
- Very specific types of applications can really benefit from using texture and local memory, but if you’re in the market for those types of memory, you probably wouldn’t be reading this blog in the first place.
The next portion of this blog will step away from the memory aspect of performance optimization and into optimizing configurations and the art of keeping all the multiprocessors on your device busy throughout the execution of your kernel.
