





This post is Topic #3 (post 2) in our series Parallel Code: Maximizing your Performance Potential.
In my previous post, I provided an introduction to the various types of memory available for use in a CUDA application. Now that you’re familiar with these types of memory, the more important topic can be addressed – accessing the memory.
Think for a moment: global memory is up to 150x slower than some of the other types of device memory available. If you could reduce the number of global memory accesses needed by your application, then you’d realize a significant performance increase (especially if your application performs the same operations in a loop or things of that nature). The easiest way to obtain this performance gain is to coalesce your memory accesses to global memory. The number of concurrent global memory accesses of the threads in a given warp is equal to the number of cache lines needed to service all of the threads of the warp. So how do you coalesce your accesses you ask? There are many ways.
The simplest way to coalesce your memory accesses is to have the N-th thread in a warp access the N-th word in a cache line. If the threads in a warp are accessing adjacent 4-byte words (float, for example), a single cache line (and therefore, a single coalesced transaction) will service that memory access. Even if some words of the cache line are not requested by any thread in the warp (e.g., several of the threads access the same word, or some of the threads don’t participate in the access), all data in the cache line is fetched anyways. This results in a single global memory access (see Figure 1).
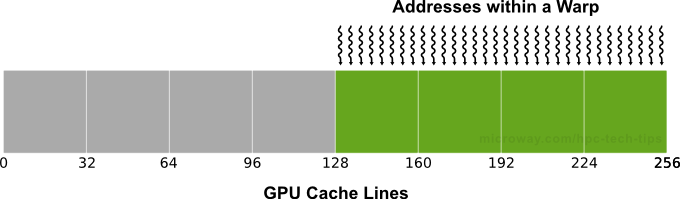
Figure 1: Aligned Memory Accesses
If sequential threads in a warp access sequential memory locations, but the memory locations are not aligned with the cache lines (overlapping), there will be two 128-byte (L1) cache lines requested. This results in 128-bytes of additional memory being fetched even though it is not needed (see the red blocks in Figure 2). Fortunately, memory allocated via cudaMalloc() is guaranteed to be aligned to at least 256 bytes. By choosing intelligent thread block sizes (typically multiples of the warp size), it facilitates memory accesses by the warps that are aligned to cache lines. This means fewer memory accesses are needed. Let your mind wander for a moment as to what would happen to the memory locations that are accessed by the 2nd, 3rd, 4th, etc thread blocks if the thread block size was not a multiple of warp size. Not good.

Figure 2: Mis-Aligned Memory Accesses
So what happens if your memory accesses are misaligned? Let’s take a look. Below is a simple kernel that demonstrates aligned and misaligned accesses.
__global__ void misalignedCopy(float *outputData, float *inputData, int offset)
{
int xid = blockIdx.x * blockDim.x + threadIdx.x + offset;
outputData[xid] = inputData[xid];
}
In the code example above, data is copied from the array inputData to the array outputData. Both of these arrays exist in global memory. The kernel here is executed within a loop in host code that varies the offset between 0 and 32. Here, global memory accesses with 0 offset, or with offsets that are multiples of 32 words, result in a single cache line transaction. When the offset is not a multiple of 32 words, two L1 cache lines are loaded per warp. This results in roughly 80% of the memory throughput achieved compared to the case with no offsets.
Another technique, similar to coalescing, is known as striding. Strided memory accesses will be discussed in the next post.
Shared Memory Bank Conflicts
If your application is making use of shared memory, you’d expect to see increased performance compared to an implementation using only global memory. Because it is on-chip, shared memory has a much higher bandwidth and lower latency than global memory. But this speed increase requires that your application have no bank conflicts between threads.
In order to actually achieve the high memory bandwidth for concurrent accesses, shared memory is divided into equally sized memory modules (also known as banks) that can be accessed simultaneously. This means any memory load/store of N memory addresses than spans N distinct memory banks can be serviced simultaneously (see Figure 3). In performance gain terms, this means that the memory exhibits an effective bandwidth that is N times as high as that of a single memory module.
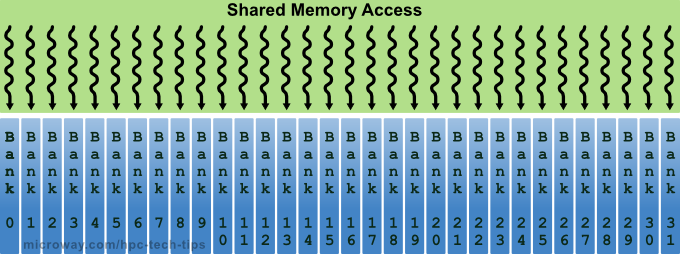
Figure 3: Simultaneous Accesses of Shared Memory
The problem however, lies in situations where multiple addresses of a memory request map to the same memory bank. When this occurs (a bank conflict), the accesses are serialized, reducing the effective bandwidth. A memory request that has bank conflicts is split into as many separate conflict-free requests as necessary, which greatly reduces the performance of the application (by a factor that’s equal to the number of separate memory requests). As shown in Figure 4, serialized shared memory accesses can take much longer.
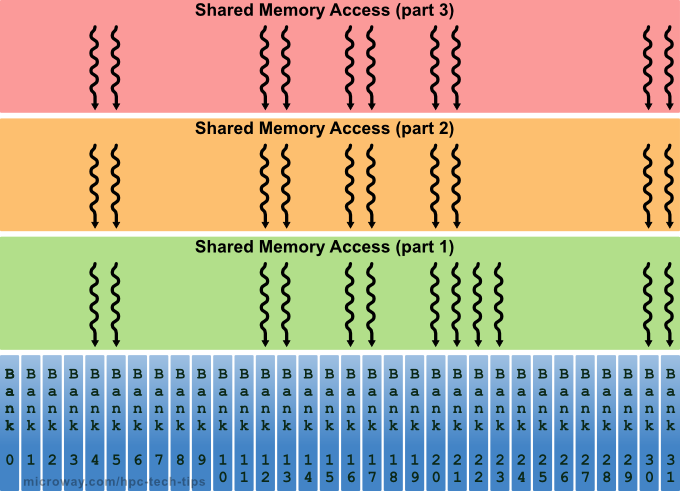
Figure 4: Serialized Accesses of Shared Memory
The only exception is the case of shared memory broadcasts. These occur when all threads in a warp access the same location in shared memory. In this case, a bank conflict does not occur.
Summary
It really cannot be stressed enough to make as much use of shared memory as possible in your application. In my next post I will provide an example that illustrates just how much faster shared memory is compared to global memory, as well as the impacts with regards to performance that result when reads to global memory are coalesced and bank conflicts are removed. In addition, I will discuss strided memory accesses, and provide some additional insight into the optimization techniques for the other types of available memory.








One Response to GPU Shared Memory Performance Optimization