





In this Caffe deep learning tutorial, we will show how to use DIGITS in order to train a classifier on a small image set. Along the way, we’ll see how to adjust certain run-time parameters, such as the learning rate, number of training epochs, and others, in order to tweak and optimize the network’s performance. Other DIGITS features will be introduced, such as starting a training run using the network weights derived from a previous training run, and using a completed classifier from the command line.
Caffe Deep Learning Framework
The Caffe Deep Learning framework has gained great popularity. It originated in the Berkeley Vision and Learning Center (BVLC) and has since attracted a number of community contributors.
NVIDIA maintains their own branch of Caffe – the latest version (0.13 at the time of writing) can be downloaded from NVIDIA’s github.
NVIDIA DIGITS & Caffe Deep Learning GPU Training System (DIGITS)
NVIDIA DIGITS is a production quality, artificial neural network image classifier available for free from NVIDIA. DIGITS provides an easy-to-use web interface for training and testing your classifiers, while using the underlying Caffe Deep Learning framework.
The latest version of NVIDIA DIGITS (2.1 at the time of writing) can be downloaded here.
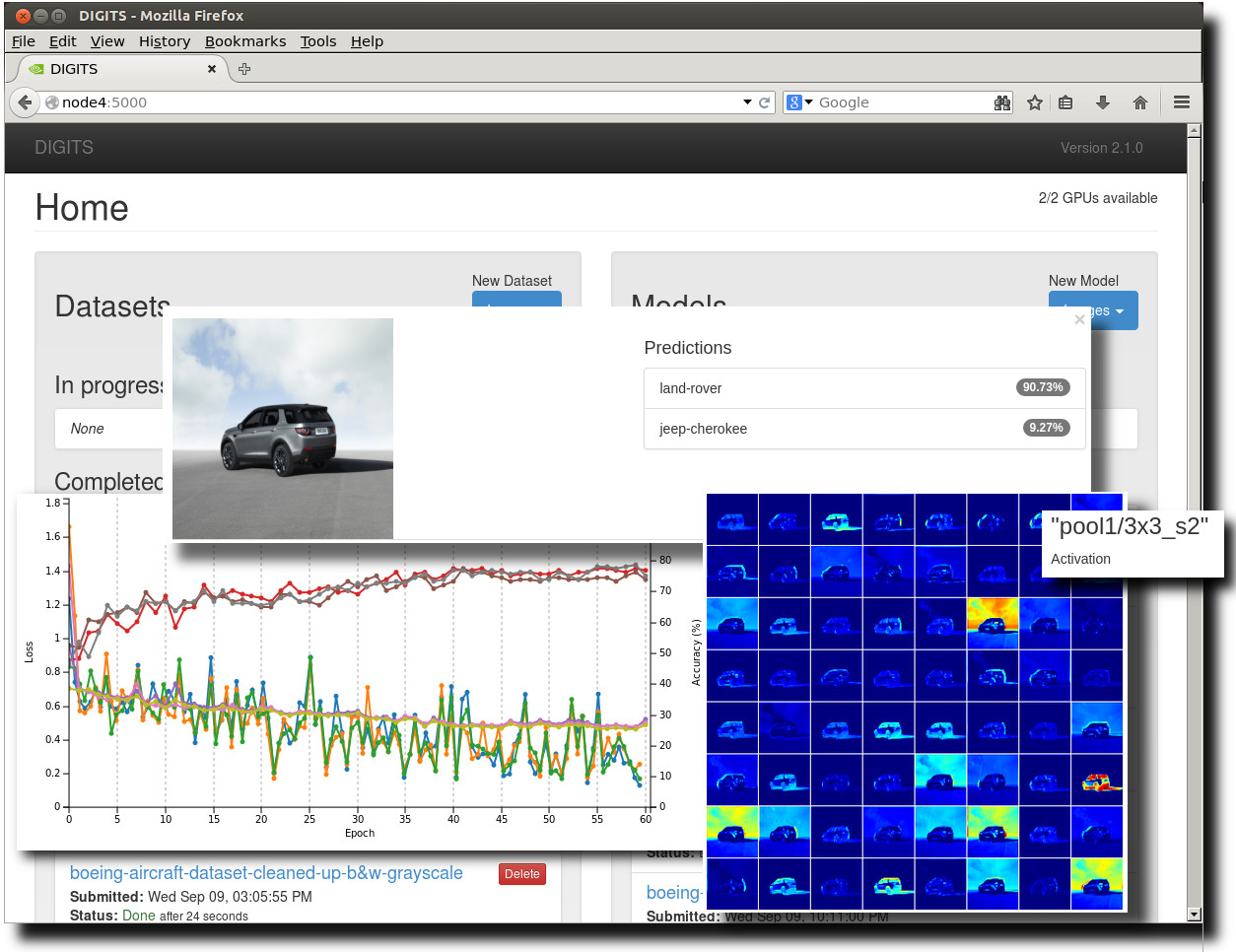
neural network distinguishes Land Rover from Jeep Cherokee
Hardware for NVIDIA DIGITS and Caffe Deep Learning Neural Networks
The hardware we will be using are two Tesla K80 GPU cards, on a single compute node, as well as a set of two Tesla K40 GPUs on a separate compute node. Each Tesla K80 card contains two Kepler GK210 chips, 24 GB of total shared GDDR5 memory, and 2,496 CUDA cores on each chip, for a total of 4,992 CUDA cores. The Tesla K40 cards, by comparison, each contain one GK110B chip, 12 GB of GDDR5 memory, and 2,880 CUDA cores.
Since the data associated with a trained neural network classifier is not heavy in data weight, a classifier could be easily deployed onto a mobile embedded system, and run, for example, by an NVIDIA Tegra processor. In many cases, however, neural network image classifiers are run on GPU-accelerated servers at a fixed location.
Runtimes will be compared for various configurations of these Tesla GPUs (see gpu benchmarks below). The main objectives of this tutorial, however, can be achieved using other NVIDIA GPU accelerators, such as the NVIDIA GeForce GTX Titan X, or the NVIDIA Quadro line (K6000, for example). Both of these GPUs are available in Microway’s Deep Learning WhisperStation™, a quiet, desktop-sized GPU supercomputer pre-configured for extensive Deep Learning computation. The NVIDIA GPU hardware on Microway’s HPC cluster is available for “Test Driving”. Readers are encouraged to request a GPU Test Drive.
Introduction to Deep Learning with DIGITS
To begin, let’s examine the creation of a small image dataset. The images were downloaded using a simple in-house bash shell script. Images were chosen to consist of two categories: one of recent series of the SUV Land Rover, and the other of recent series of the Jeep Cherokee – both comprised mostly of the 2014 or 2015 models.
The process of building a deep learning artificial neural network image classifier for these two types of SUVs using NVIDIA DIGITS is described in detail below in a video tutorial. As a simple proof of concept, only these two SUV types were included in the data set. A larger data set could be easily constructed including an arbitrary number of vehicle types. Building a high quality data set is somewhat of an art, where consideration must be given to:
- sizes of features in relation to convolution filter sizes
- having somewhat uniform aspect ratios, so that potentially distinguishing features do not get distorted too differently from image to image during the squash transformation of DIGITS
- ensuring that ample sampling of images taken from various angles are present in the data set (side view, front, back, close-ups, etc.) – this will train the network to recognize more facets of the objects to be classified
The laborious task of planning and creating a quality image data set is an investment into the final performance quality of the deep learning network, so care and attention at this stage will yield better performance during classifier testing and deployment. The original SUV image data set was expanded by window sub-sampling the original set of images, and then by also applying horizontal, vertical, and combined flips of the sub-sampled, as well as of the original images.
Neural Network Image Classifier Performance Considerations
Beforehand, some performance-oriented questions we can pose are:
- Can the classifier distinguish SUV type from front, back, side, and top viewpoints?
- To what level of accuracy can the classifier distinguish image categories?
- What sort of discernable, high-level object features will be learned by the network?
(We recommend viewing the NVIDIA DIGITS Deep Learning Tutorial video with 720p HD)
GPU Benchmarks for Caffe deep learning on Tesla K40 and K80
A GoogLeNet neural network model computation was benchmarked on the same learning parameters and dataset for the hardware configurations shown in the table below. All other aspects of hardware were the same across these configurations.
| Hardware Configuration | Speedup Factor1 |
|---|---|
| 2 NVIDIA K80 GPU cards (4 GK210 chips) |
2.55 |
| 2 NVIDIA K40 GPU cards (2 GK110B chips) |
1.56 |
| 1 NVIDIA K40 GPU card (1 GK110B chip) |
1 |
1compared against the runtime on a single Tesla K40 GPU
The runtimes in this table reflect 30 epochs of training the GoogLeNet model with a learning rate of 0.005. The batch size was set to 120, compared to the default of 24. This was done in order to use a greater percentage of GPU memory.
In this tutorial, we specified a local directory for DIGITS to construct the image set. If you instead provide text files for the training and validation images, you may want to ensure that the default setting of Shuffle lines is set to “Yes”. This is important if you downloaded your images sequentially, by category. If the lines from such files are not shuffled, then your validation set may not guide the training as well as it would if the image URLs are random in order.
Although NVIDIA DIGITS already supports Caffe deep learning, it will soon support the Torch and Theano frameworks, so check back with Microway’s blog for more information on exciting new developments and tips on how you can quickly get started on using Deep Learning in your research.
Further Reading on NVIDIA DIGITS Deep Learning and Neural Networks
1. Srivastava, et al., Journal of Machine Learning Research, 15 (2014), 1929-1958
2. NVIDIA devblog: Easy Multi-GPU Deep Learning with DIGITS 2 https://devblogs.nvidia.com/parallelforall/easy-multi-gpu-deep-learning-digits-2/
3. Szegedy, et al., Going Deeper with Convolutions, 2014, https://arxiv.org/abs/1409.4842
4. Krizhevsky, et al., ImageNet Classification with Deep Convolutional Neural Networks, ILSVRC-2010
LeCun, et al., Proc. of the IEEE, Nov. 1998, pgs. 1-46
5. Fukushima, K., Biol. Cybernetics, 36, 1980, pgs. 193-202







